2019 ECUG 参会总结和感想
在部门的支持下, 有幸参加了2020年初在杭州举办的第12届ECUG, 提炼一下内容, 谈谈收获和感想.
内容提要
简单总结一下各位老师分享的内容, 内容我整理过, 不保证完全还原讲师的原意, 但大差不差.
1. Coding 吴海黎 - 微服务拆分
讲师主要介绍了Coding从单体服务架构到微服务架构的演变过程.
Coding早期为单体服务架构, 话虽如此, 但实际上由于业务需要和多技术栈(Java+Go)也是分成几个大服务的, 依赖Etcd和gRpc, 服务有拆分, 没有治理, 耦合严重, 遇到的问题主要是迭代缓慢, 稳定性差, 组织架构难以管理.
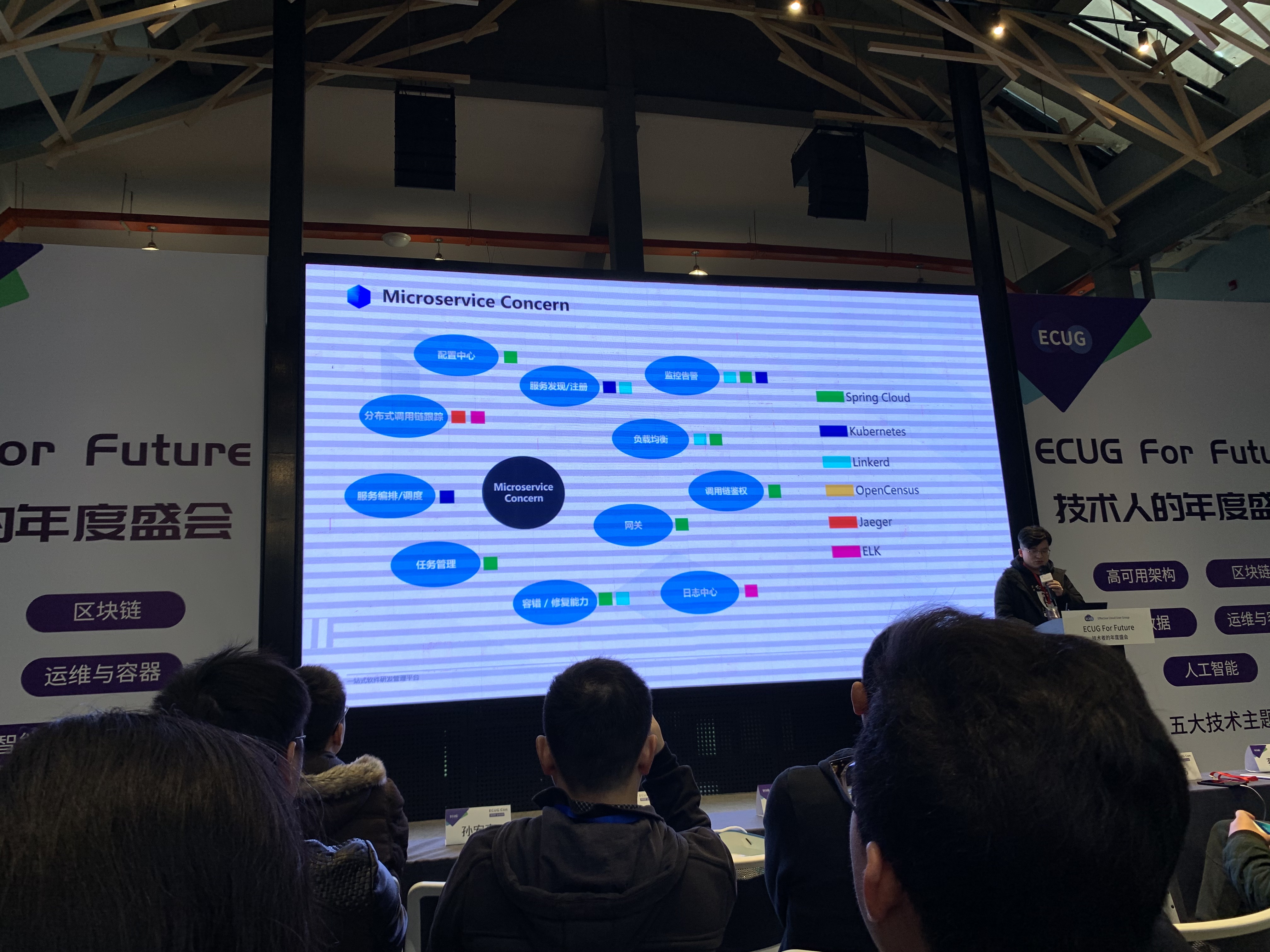
失败经验
在微服务如何拆的问题上, Coding有两条失败后总结的经验
- 聚焦核心目标进行增量式拆分, 不做无意义拆分. Coding最初拆分细到Table级别, Rpc性能消耗严重, 无法支撑业务.
- 不应当把服务拆分和产品迭代完全拆分, 否则后期问题很多, 代码合并成本高, 影响团队信心.
微服务的拆分无法一次性完成, 应当从最重要的领域开始, 循序渐进, 开始的时候重点在于是验证基础设施的可行性.
目前方案
Coding对比了Spring Cloud+K8S和Linkerd+K8S方案, 基于自身情况和保持对架构无侵入性的目的, 选用了后者.
Coding有100+服务, 出现错误后需要快速定位, 分布式追踪方案使用的是OpenCensus. 数量众多的服务无法在本地开发环境全部启动, 解决方案为Telepresence(没了解过, 学到了…), 基本原理是在集群中新增Pod作为代理, 将集群流量打到本地调试.
Coding使用Hystrix + Prometheus的监控方案.
成果
从每天一个版本都发不了, 到现在可以随时根据需要发版.
2. PingCAP 刘奇 - Chaos Engineering
讲师主要介绍如何通过Chaos Engineering的思想构建高可用服务.
不可靠的必然性
刘奇首先介绍了TiDB目前的发展情况, 并提及数据库开发过程会遇到各种各样想象不到的问题, 比如来自操作系统, 文件系统, 编译器的Bug. 比如下图中的表格就记录了他们在不同文件系统下找到第一个Bug所需要花费的时间(可以看出Ext4果然还是非常稳定的, Xfs也不赖):
随后他提到Chaos Engineering的概念, 即从最一开始就不应当假设外部环境正确性, 从而保持应用的“容错”能力. 他以Netflix开源的Chaos Monkey举例, 该项目会随机Kill指定环境中虚拟机或容器, 来模拟出错场景, 健壮的应用应该能够在这种环境中保持预期内定义的行为.
Chaos-Mesh
随后他介绍了PingCAP针对K8S的Chaos Engineering项目Chaos-Mesh, 可以在K8S集群中随机模拟各种错误场景, 包括CPU或内存耗尽, 网络分区, 文件系统出错, 带宽降低等, 以测试集群的稳定性, 尽早暴露潜在的问题. 该项目曾居当日GitHub Trending Go 1st和Hacker News热榜.
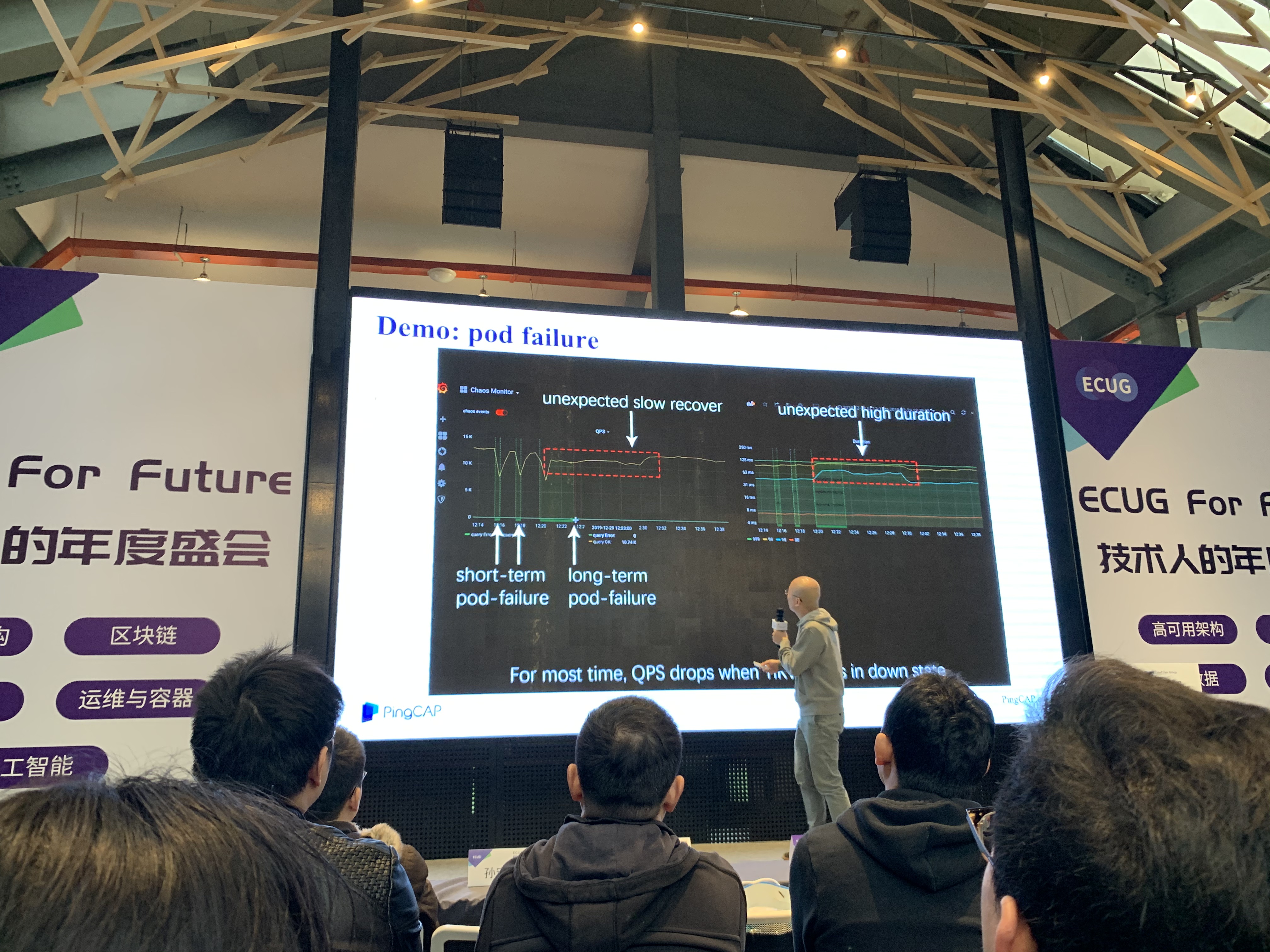
轶事
演讲过程中几次因为设备问题投影黑屏, 刘奇开玩笑说这就是“黑天鹅”. 他在演讲中也提及, PingCAP目前也已经All in K8S, 因为在美国使用K8S已经成为当前时代的一种“政治正确”. 另外, Chaos-Mesh的作者看起来似十分年轻(相比之下年龄相仿的我就比较废物了…).
3. 七牛许式伟 - 快速构建应用
讲师主要介绍如何通过理解架构的方式实现快速构建应用.
云计算的发展和影响
许式伟将云计算的发展分为三个阶段:
- 1.0 机器计算时代, 代表为2007年的AWS, 开发者从云服务商租借云主机.
- 2.0 容器计算时代, 代表为2014年云原生概念的发展和K8S的Release.
- 3.0 应用工厂时代, 即如今生产力随着基础设施的发展而加速, 应用可以批量生产的时代.
许式伟认为“IT普惠”已经真正的到来, 云原生在国外已成为发展的必然选择, 在国内近两年也会有大的发展. 这将对人员组织架构有以下影响:
- 基础设施越来越完善, 服务端开发工程师需求将大幅降低.
- 全栈式开发工程师和架构师需求将上扬.
- 数据分析工程师需求将上扬.
互联网企业从起步至今只有20年, 已经发生了巨大的变化, 20年后发展成什么样更加难以想象. 他认为这个过程的前半程是IT效能的极大释放, 而从现在开始的后半程将转向数据效能, 这也就是他提出前文预测的原因.
架构和如何快速构建应用
许式伟认为架构的核心在于开闭原则(OCP), 也就是想清楚稳定点和变化点. 他以CPU举例, 正由于区分并设计了指令集的不变形和指令序列的多变性, 才能够做到解决一切可以用计算解决的问题. 应用架构的设计中必须要认识到的一点是, 计算是稳定的, 数据和计算的组合方式是多变的, 如何才用稳定的技术架构来面对一轮一轮的交互革命.

架构设计的本质, 是提炼系统的核心功能. 核心应当是稳定的, 不能随便添加或修改功能, 否则不符合OCP原则, 在未来是无法适应变化, 也无法维护和扩展的. 遵循“只读设计”是良好的实践, 比如当今火热的云原生, 也是“只读设计”趋势下的产物. 架构的治理类似于把整个系统变成对只读组件的“搭积木”过程, 让接口本身足够稳定但易于组合.
许式伟又从编程语言的角度举例, 说C语言在50年历史中核心部分没有发生大的变化, 而C++则历经数次变革, 至今仍在尝试定义新的规范. 七牛之所以推崇Go, 是因为他们认为Go也符合C的哲学. 许式伟说, 拥抱变化的核心在于理解变化的本质, 找到变化中不变的东西, 而不是“追逐变化”. 我非常赞同他的这句话.
4. 知乎马嘉利 - 图像算法在内容社区的应用
讲师主要介绍图像算法在知乎的选型和应用场景. 这是我个人今天最期待的分享, 我在大学时期就对CV有非常大的兴趣, 并且至今依然觉得是未来最有前景的方向之一.
马嘉利首先列举了图像识别在知乎应用的几个典型场景.

首先是特征识别, 典型场景是色情图片识别, 知乎的方案是Blinear CNN双线性池化来提取细粒度特征.
其次是OCR, 典型场景是嵌入图片的广告或表情内的文本涉政, 知乎会进行限制, 技术方案是基于像素语意分割的EAST, CNN+RNN+CTC, CNN学习特征, RNN学习字符先后顺序, 翻译层从特征序列得到字符串编码, 数据集为合成数据集.
另一个场景是图片展示, 典型场景是对热榜和回答配图. 现在信息量极速增长, 图片和短视频更能迎合用户喜好, 因此从内容中选择更具吸引力的配图或封面是知乎作为文字社区的必要需求. 知乎的解决方案是, 首先由设计师讨论出一个评价标准, 并对数据进行标注, 作为训练集. 训练的评分模型支持任意尺度图像输入, 多层次特征提取, 在回归层通过3FC预测分数. 马嘉利提到, 这个场景在知乎的应用还不是很好, 推测的原因是设计师指定的评价标准与用户实际体验存在差异, 后续计划通过合理的埋点方式对用户行为进行记录, 生成训练集以改进效果.
最后一个场景是智能裁剪, 典型场景是根据原图自动生成Banner或封面. 考虑的方面包括避免裁切人脸等. 数据集也是由人工先标注高分区域, 然后通过移动窗口降低分数的方式构造训练集.
马嘉利还回答了关于为何不直接使用云服务的问题, 包括两方面: 首先, 云服务不能满足需求, 比如NLP方面, 云服务目前仅能提供政治敏感, 色情内容的识别, 但知乎有判定回答是否优质的定制化需求. 其次, 内容作为商业机密需要被保护. 他还提到知乎的全部数据都在网信办监管下, 大家在网络上应当谨慎发言. 谈到未来的发展, 他说知乎目前仍以NLP为主, 但会加大图像和视频方面的投入, 以迎合发展趋势.
5. Apache Kylin 韩卿 - 云原生
讲师首先介绍的Apache Kylin.
Kylin的思路
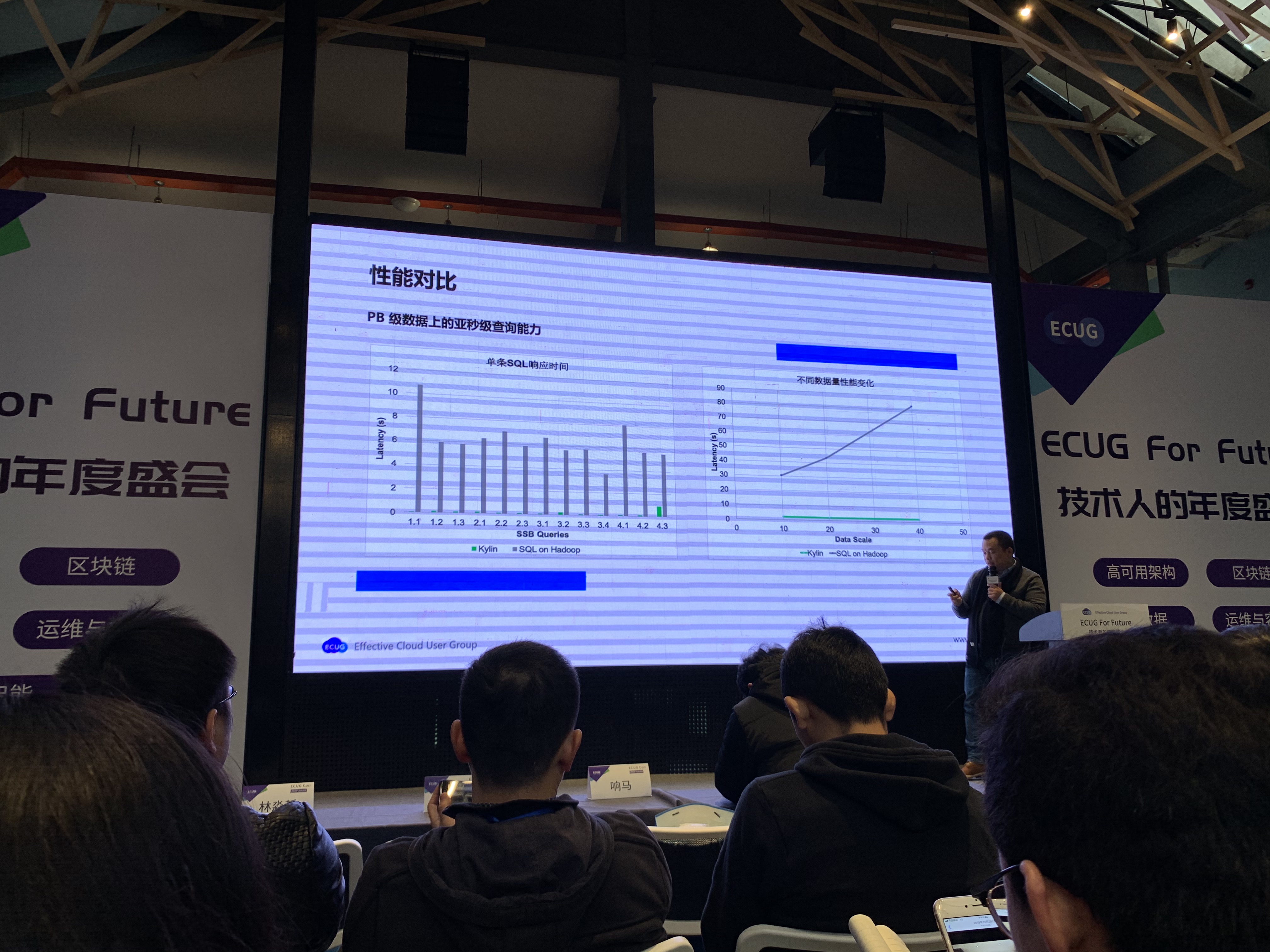
韩卿认为, 大数据永远是一种Trade Off, 代价就是预计算, 也就是空间换时间. SQL的本质是代数, 比如5个字段, 那么对于一定操作集来说组合的可能性是一定的, 列举场景并根据可能性进行剪枝, 进而执行预计算, 通过这样的方式, 在实践中有时可以提速90%以上. Kylin的核心思想就是基于此, 通过将数据抽取到Cube中, 让大多数SQL的执行从Table->Join->Filter->Aggravations->Sort简化为From Cube->Filter->Sort, 从而提升性能.
Kylin的发展
Kylin是国内最早的Apache顶级项目, 韩卿认为目前国内开源力量发展很好, 并表示Kylin近段时间一直保持了近45˚的增长.
Kylin最初依托于Hadoop生态, 但存在明显的局限:
- Hadoop本身有些反云原生.
- Hadoop学习曲线陡峭, 生态涉及200+个开源项目, 想在实践中玩转至少需要熟悉其中1/3.
- HBase为写优化, 不是真正的列存.
总结就是Hadoop在Local可以工作的很好, 并且成本较低, 但没有适应云环境. Kylin的发展经历了几个阶段:
第一步, 2013年进行重构, 面向接口编程, 采用可插拔设计, 最早只支持Hive作为数据源, 现在已经可以支持各种数据源.
第二步, 2015年使用Spark替换MapReduce, 做了很多优化工作, 平均性能更好.
第三步, 2016年将项目Docker化.
第四步, Kubernetes化.
第五步, Parquet替换HBase, 由于设计优良, 替换工作很快, 但成熟很慢, 总结: 不亏.
第六步, 查询分布式化, 最早使用流行方案 - Apache Calcite作为Parser, 内部没有并发, 改进为基于Spark DF的分布式方案, 这一步最复杂.
今年的目标: 真正云原生, 真实时, 同时支持批处理和流处理.
6. Fibos响马 - 区块链
我觉得这位老哥分享的内容从技术上来讲没什么深度, 从观点上来讲不尽正确, 所以没有记录.
7. Google Ross - 分布式场景实践问题
讲师主要介绍Google在分布式场景下的一些实践经验. Ross是Google大佬, 个人十分期待.
业务流程和结构
Ross首先分享了Google搜索业务 1000000+QPS场景下的架构, 首先是Indexing的基本流程, 可以描述为Craw->Render->Annotate->Dedeuplication->PageRank &…->Aggregate->Sort, 即首先爬取, 然后进行渲染, 需要这一步是因为现代网页存在大量异步加载内容, 之后是根据网页结构进行标注, 如找出页面的Real Title, Out Links等, 然后进行去重, 去重的算法没有提及, 但我曾在吴军的书中读到, 也在我的博客中分享过如SimHash的算法. 之后是我们都比较熟悉的大名鼎鼎的PageRank等一些算法, 最后进行聚合和排序.
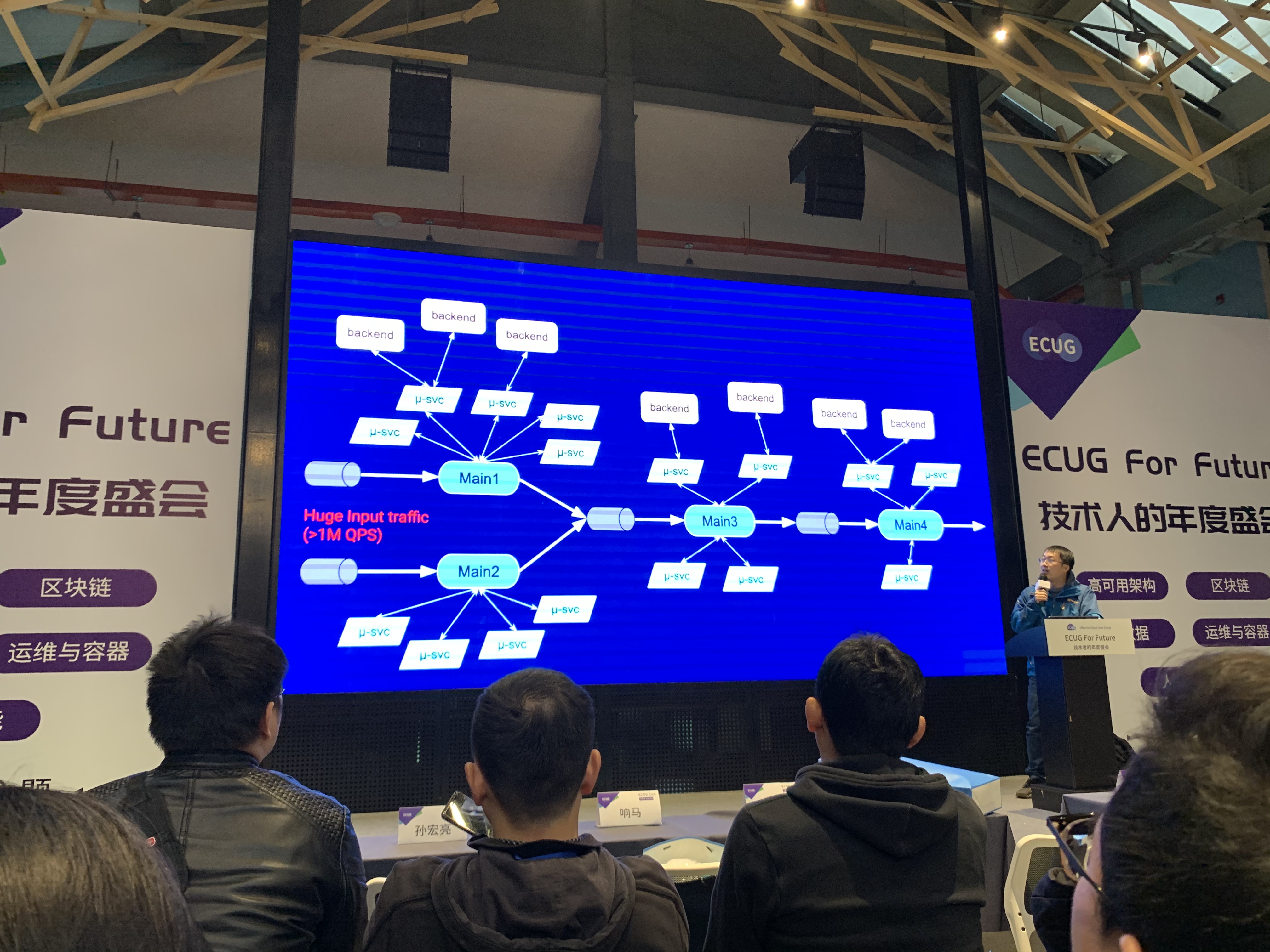
上图只是一个简化的服务内部结构, 可以看出Google内部存在大量服务, 服务有不同的角色, 存在星形的依赖关系, 并且数据整体的流动是单向的, 中间靠消息队列衔接.
实践中遇到的问题
首先, 用消息队列解耦服务, 但缺少全局的Flow Control, 在最初的Resource调节机制中, Resource Manager会自动给负载较高的节点分配更多的Resource, 会有场景下出现负向反馈, 即这种HotSpot会在Node间移动, 这是不合理的. 我自己在阅读微服务架构相关材料的实际常见人提到没有熔断机制的系统, 错误在服务间扩散最终导致集群瘫痪的问题, 但却没有想过这种高资源消耗的正常执行Job在整个流中堆积后产生的HotSpot效应.
其次, 这种环境下Debug比较困难, 会有Error Propagation问题(多级错误信息嵌套导致难以理解). 在错误的处理上, Google不仅会对出错的Case进行Reprocess, 还会统计Query被Reprocess的次数, Reprocess次数超出限制的Death Query, 还有名为Hospital的机制, 即队列话化的在Resource更多的机器上抢救一次, 这一行为主要是应对那些本身非常复杂, 在常规处理流程中可能因为执行时间过长而被Kill的网页, Hospital中也将记录更多的日志信息.
最后, 他还提到了Protobuf中现存的一些问题, 如2/3版本选择, 以及如Protobuf 3中Drop Unknown Field特性在多层Proxy后存在属性丢失隐患等细节问题.
Go vs. Modern C++

Ross表示, 尽管他个人很喜欢Go, 但Google内部C++生态已经非常完善, Go仍有较大差距. 由于Go的GC, 以及Go Memroy Layout和C++ Memory Layout的差异造成的额外序列化和反序列化, 用Go替换C++服务后实际导致了近30%的性能和资源浪费, 这些原因也同时导致了Golang和Protobuf在内部推进存在阻力.
8. 阿里巴巴孙宏亮, 孙健波 - Kubernetes 应用管理
讲师了介绍了OAM的概念并分享了阿里巴巴的解决方案.
阿里巴巴大规模容器化过程
- 2011年基于LXC自研T4, 2013年初步探索, 构建了AI集团管理系统.
- 2015年野蛮生长, 内部确认了容器化后带来的好处, 发展出包括AliSwarm, Zeus和Hippo等运维平台, 极大降低了运维成本.
- 2017年统一集团资源池, 构建了Sigma调度系统, 收敛了多个运维平台的资源调度, 大幅降低了数据中心的资源成本.
- 2018年转型Kubernetes.
- 2019全面拥抱云原生, 基于Kubernetes的生态在阿里内部蓬勃发展, 双十一活动中的很多流量已经落在K8S上.
OAM与Rudr
孙洪亮也提到了目前的一些挑战, 比如Kubernetes自身Api和扩展的复杂性, 很多企业基于K8S进行二次封装, 搭建自己的运维平台. 剩余的大部分时间, 他和阿里的另一位讲师主要在推广他们基于K8S的OAM实现 - Rudr, 我之前没有了解过这方面的内容, 就他的分享而言, OAM的主要目的在于关注点分离.
他通过一个依赖ZooKeeper的应用进行举例, 认为现有的K8S Yaml文件过于复杂, 既包含了少数开发人员关心的依赖参数, 也包含了ZooKeeper运维人员对ZooKeeper的一些配置参数, 还包含了K8S运维人员针对K8S组件的配置选项:

接下来就是对Rudr相关功能的介绍和演示, 我没有记录.
9. 滴滴蔡金平 - 云+端机器学习加速
讲师主要介绍滴滴云+端机器学习加速引擎IFX的基本思路.
场景和问题的难点
蔡金平首先列举了在滴滴内部AI算法的一些应用场景, 如路径规划, 司机人脸识别, 司机驾驶证身份证合一识别, 车辆驾驶证合一识别等.
然后他认为滴滴在实践中存在两个难点:
- 滴滴对算法的延时要求比较高.
- 设备多样性: 在云上有Nvidia和x86服务器, 在端处有Andorid, iOS和各类车载设备.
滴滴云+端机器学习加速方案
蔡金平表示, 现在AI领域各式各样的框架很多, 滴滴内部选择多样, 并没有特别的限制, 内部有一套生态对模型进行优化, 对算法执行进行监控和评估, 并且现在已经独立伟产品, 即滴滴云上的IFX和EIS.

他简单介绍了IFX的优化思路:
- IFX-Transform: 完成图到图的转换, 统一各个框架的数据结构, 优化以提升计算的访存比.
- IFX_Autotuning: 根据设备类型调整并进行汇编优化.
- IFX-Slimming: 通过降低精度, 稀疏化, 裁剪和降维模型来进行瘦身.
- IFX-Profiling: 可视化分析指导瓶颈点优化.
- IFX-System:
- CUDA Stream并行化调度优化.
- 线程级图融合, 即Launch的Kernal数量超过GPU计算单元时通过队列进行并发控制.
- IO优化.
内部成果主要对标开源项目, 经过一系列优化通常会相较后者有比较大的提升.
我工作之后ML这一块就很少接触了, 坦诚地说对于他讲到的不少优化细节, 除了像在卷积层把Int32的原始数据降到Int8或更低位数来减少PCIE消耗, 小模型GPU打不满要做外部的并发控制这种比较简单的方法外, 基本都是完全没听懂, 也没来得及做详细记录.
10. 网易冯常健 - ServiceMesh落地关键点总结
讲师首先讲了ServiceMesh的发展历程, 总结一下就是:
ServiceMesh的发展现状
2016至2018年仍是布道为主, 到2019年才在大公司落地.
网易为什么选择ServiceMesh
集团产品众多, 内部以事业部划分, 业务和技术栈多元化, 目前以Java为主, 存在少量Go/Python/Node服务, 存在以下痛点:
- 网易微服务建设起步早, 使用了很多私有技术, 云原生时代到来后技术栈升级成本很高.
- 服务治理对业务侵入性很大, 研发关注点很多, 包括服务发现, 熔断等框架性的东西很多, 开发工作效率很低.
- 中间件和SDK的升级需要推动业务方配合, 工作量大, 周期长.
- 多语言需求凸显, 治理体系难以统一, Java生态已经成熟, 但Node/Go差距较大.
- 从集团角度出发, 微服务支撑体系重复建设, 未形成技术资产.
网易寻找解决方案的出发点:
- 符合云原生趋势.
- 提供一定的能力下沉能力, 业务和架构支撑解耦, 提供服务独立运维能力.
- 平台化, 统一技术栈, 沉淀技术资产, 形成集团通用的产品.
基于前述原因, 最终选择了引入Service Mesh, 在具体技术选型上, 主要关注:
- 拥抱云原生, 遵循开放标准, 选择社区活跃可叠戴的项目.
- 高性能表现, 关注Sidecar TPS延时和资源占用.
- 需要在数据面和控制面具有可扩展性, 支持控制中心或有Open Api.
冯常健还总结了在团队中引入Service Mesh的前提条件:
- 组织文化上要有较远的视野, 对新技术敏感, 理解和认可Service Mesh的深远影响力. 整个改造过程中间可能是混乱的, 甚至比不改变时还要糟糕, 会有负面意见出现, 研发团队要有价值观和信心, 相信技术可以改变现状, 最终会是一个旧标准->混乱->实践和整合->新标准的过程.
- 容器化, 微服务和DevOps在团队内必须已经成熟.
落地的关键点
这一块冯常健讲的比较多也比较细, 我没来得及做详细的记录, 只粗略的列一下大纲.
服务通信
需要支持异构协议:
- Http
- Rpc(Dubbo, gRpc, 基于Netty实现的私有协议)
- Redis, Kafka等第三方协议
网易对相关框架尽心了深入的研究和改进, 比如去掉了Dubbo中的服务发现和负载均衡等特性, 因为在Mesh层已经提供了这些功能.
平滑迁移
这一步主要是要允许Mesh内外服务混用, 消除业务方的顾虑, 并提供一定的兜底策略.
方案是扩展Istio, 定制Envoy路由分发, 引入边界Api Gateway.
Api Gateway
需要有能力更强的Api Gateway来支撑认证, 鉴权和限流等特性, 要具备可观测性, 要提供扩展性, 定制路由, 缓存策略, 支持请求篡改, 加解密和反爬. 性能上对标Kong, 要求远大于后者. 要有多租户支持, 有与Mesh统一的控制面.

方案是基于Envoy进行改进, 补充了C++ Plugin和Lua Plugin, 最终实现了在8C8G服务器上达到12w TPS.
性能优化
主要分享了针对Mesh内部路由和Envoy的优化策略, 目的是满足C端对延时的需求, 讲的比较快, 我没有详细记录.
成果和展望
冯常建提到, 使用Service Mesh并没有降低整个架构的复杂度, 但由于很多能力下沉到Mesh层, 因此极大的降低了各个应用的复杂度. 目前, 这套方案已经经过双十一大促, 大事件等大规模高并发超劲的验证, 大大提升了满载稳定性, 提升了运维效率. 通过解耦框架和业务, 统一了多语言治理体系, 研发的关注点减少, 降低了微服务架构支撑的技术复杂度.
对未来的发展, 冯常健希望能够进一步提升服务端技术对业务开发人员的透明度, 使团队招人更加容易. 从技术上, 他希望随着Service Mesh在公司的应用和在社区的成熟, 逐渐解决以下问题:
- 中间件和基础服务可进行业务无感升级.
- 无侵入式的流量染色和全链路压测.
- 通过流量回放进行线上全量回归验证.
- 无人值守故障演练.
- 打通从应用到基础组建, 从内核到网络数据的可观测性.
11. Databricks 范伟臣 - Spark 3.0 更新总结
讲师主要介绍Spark 3.0中的新特性, 也提到了一些Spark性能优化的注意点.
Spark 3.0
具体内容基本和网上流传的“更新日志”差不多, 加上范伟臣讲解的节奏比较快, 所以我也没有做详细的记录, 只总结一下影响比较深的点. 先放一张图:

在我看来Spark 3.0主要做了几件事情.
优化了性能
这点上包括引入了Dynamic Partition Prunning, Adaptive Query Execution等新特性. 前者可以在实际Join前通过运行时参数生成Filter, 减少后续实际参与Join的数据量. 后者可以在Shuffle时动态调整Partition的数量, 避免Partition定义不合理导致Reducer实际处理的数据量不足或在HDFS上大量读写小文件造成性能浪费. 两点都可以说是弥补了Spark 2.x在Runtime级别优化的不足, 在特定场景下确实可以带了比较大的性能提升, 此外还有其他优化, 我没有记录, 可以直接看社区的总结.
加强了在机器学习方面的能力
也是比较明显的趋势, 比如对Python支持的补充, 加入GPU支持, 推出Koalas等. 比如我平时做实验很少会用Spark, 毕竟Python下的一套工具实在是太顺手了, Spark社区显然也认识到了这一点, 这次顺带推出的Koalas其实就是为Spark提供了一套和Pandas一致的接口.

全新的DataSource Api和更好的ANSI SQL兼容性
这两点也值得一提, 后者会让Spark表现出与之前不一致的行为, 比如对于一些脏数据, Spark 2.x可能会在无法计算时使用null, 但Spark 3.0会直接抛出错误.
Join性能优化
Spark提供了多种Join方式, 不同的Join方式适合不同场景, 如大小表, 数据倾斜等. 针对数据特性选用合适的Join方式可以带来非常明显的性能提升. 比如一个直观的例子, 对于大小表Join, 使用Broadcast Hash Join会把小表进行广播, 从而避免数据在节点间Shuffle, 速度非常快. 具体可以看下图:

12. 阿里巴巴曹龙 - 云原生数据湖分析服务
讲师主要来推销阿里云的Data Lake Analytics服务.
本来是挺期待的, 毕竟讲师名字叫”封神”, 不过他这次看起来只是来推销阿里云的产品的, 名字比较长就简称为DLA吧, 其实也是现在比较流行的Serverless概念的又一款FaaS产品, 借鉴对标AWS的Athena, Azure的Data Lake Analytics和Google Cloud的BigQuery, 可以简化的理解为云计算时代下的动态阔缩容, 按需付费数据库或计算引擎.
演讲的内容不外乎也就是官网宣传页那些东西了, 所以我也没有做详细的记录, 放一张曹龙总结的数据库发展趋势图吧, 另外还有一个目前数据库的排名, 他截了DB-Engines网站的图, 我直接贴个链接好了.

曹龙提到一点, 就是就现在的趋势而言, 云计算服务商提供的基础设施越来越齐全了, 互联网公司发展的趋势也是逐渐看中轻资产和低成本, 没什么技术力的小公司以后可能真的像之前许式伟说的一样, 服务端只需要招几个SQL工程师就好了.
13. MobTech 林淼哲 - 联邦学习
讲师主要分享机器学习的一个分支 - 联邦学习.
机器学习落地过程中的一个问题是, 模型需要数据去训练, 而数据往往被多个不同的企业或主体持有, 如何在保证各方数据安全的情况下共同参与计算. 再往简单说, 就是怎么样让你帮我算, 还不让你知道我的原始数据. 其实这个过程比表面看起来的还要复杂一些, 首先要保证计算结果的正确性, 其次要保证对方不能通过概率分布或其他数学手段反推出原数据, 这些都不是简单的哈希或混淆能够解决的. 林淼哲表示研究这个问题的目的, 主要是为了向客户提供一种可证明的, 数据安全的计算方式.
林淼哲故意讲的比较谨慎, 防止大家听不懂(虽然我觉得估计还是没几个人能听懂过, 毕竟方向比较小众), 不过我读大学的时候研究过一点这方面的知识, 毕设课题做的也是《隐私保护的共享协同过滤算法研究》, 其实和他今天讲得东西刚好是一个方向, 甚至还写过几篇博客, 所以压力不是很大.
过程基本是数学推导, 有意深入的同学可以自己Google一下联邦学习, 目前的实现还不是特别复杂, 在这就不整理了. 我之前也有一个项目是基于加同态实现类似的效果, 代码很短, 感兴趣的话也可以看一下.

14. Worktile 孙敬云 - 敏捷开发和团队管理
正如标题, 讲师主要介绍敏捷开发和团队管理, 其实他讲之前我对这个话题是不太感兴趣的, 因为我上大学读的就是软件工程专业, 专业课基本都是软件体系结构和敏捷开发, 极限编程相关的内容, 这个可能对那些准备转向管理的人比较有用, 但是我是一个只想一心钻研技术的人.
不过孙敬云演讲能力真是不错, 硬是让我认认真真听完了, 内容比较多也比较具体, 甚至包括目录结构和分支策略等, 我同样只列个大纲, 这个比较适合直接去看PPT.

我这里只总结觉得比较有意思或值得关注的观点和做法:
计划性的任务应当是团队的主流, 如果总是存在大量“即紧急又重要”的临时任务, 那么团队是危险的.
Worktile内部随时保持一个可以上线的版本, 每个迭代比较小, 有问题随时回退, 区分多个版本:
- Alpha - 可用
- Beta - 稳定
- Canary - 用户可体验, 与Production共用DB以便于滚动升级
- Production - 所有人可用
要保持20%的非功能性需求, 把团队技术力作为战略, 团队本身也是一款产品.
团队内部目前不按角色区分成员, 前端/后端/运维的工作每个人都可以做.
内部有Chaos Engineering实践, 如用来测试团队多久可以响应某种程度的错误.
数据兼容策略是双写, 每次升级都要求考虑可逆性.
线上出问题, 先通报后处理, 以达到信息共享, 提高解决效率;先止损后查因, 保持随时回退的能力.
错误的责任是整个团队的, 要让每个成员又更高的全局观.
DevOps不是基础设施, 不等于K8S+CI, 而是一种流程改进方式和团队文化.
自动化测试维护成本很大, 积极性不高, 因此只要求关注Happy Case, 更注重单元测试和集成测试.
15. 同盾科技吴万港 - 基于区块链的可信计算
讲师主要介绍区块链技术和在国内的应用. 显然这个人的技术力非常强, 和昨天那个讲区块链的老哥应该完全不是一个级别. 不过我只听了个开头就因为要赶高铁的原因提前离开了, 比较可惜.

收获和感想
总的来说两天收获还是比较大的, 感觉水平高的人看问题视角高很多, 思考也深入很多, 有大量值得学习和深入研究的东西, 很开阔眼界. 感谢部门提供的这次机会吧, 之后有时间感觉自己也可以多去参加这类活动, 学习新的知识, 了解行业技术动向.
架构方面, 从许式伟介绍“开闭原则”, 到韩卿的“可插拔设计”, 到孙洪亮的“关注点分离”, 再到冯常健对“无感”, “无侵入”的反复强调, 角度基本和我个人的理解是一致的, 只有维持高内聚低耦合的原则, 把握现象背后的本质, 才能让一个架构设计有能力长期应对业务规模的增长和技术的革命. 这也符合目前技术演进的趋势, 从后端RESTful的接口设计模式, 前端MVVM框架的流行, 到容器化和容器编排, GraphQL和各类网关类项目的兴起, 从Spring MVC到Spring Boot再到Spring Cloud, 不外如是.
技术方面, 我在读大学的时候接触过Kubernetes, Spark和Kylin这些开源项目, 但也都是读文档和在社区看别人讨论问题, 这样近距离听各位大佬分享实践经验的机会还是非常珍贵的, 学到了不少解决问题的思路, 也了解了一些实际工作中的解决方案.
许可协议: CC BY-NC-SA 4.0
本文链接:https://blog.angelmsger.com/2019-ECUG-参会总结和感想/