Spark的流计算方案 - Sturctured Streaming
Spark是一个我们比较熟悉的分布式计算引擎了, 本身没有特定目标限制, 从数据清洗, 转换, 机器学习到图计算都提供不同程度的支持, 相较于其诞生之初的主要对手Hadoop MapReduce而言有更高层次的Api封装以及内存级别的速度. 在简道云中主要承担ETL相关的计算任务.
本文的主要目的在于研究其流计算解决方案Structured Streaming, 但也总结了作为基础的Spark核心概念.
这是不是一篇深入探索特性的文章, 后文提及的内容大致不超过官方文档的范围, 因此如果你已经完整阅读过官方文档相关内容, 可以忽略以节省时间. 这也不是一篇快速上手教程, 后文不会提及如何建立Spark集群, 如果需要可以参阅官方文档中提供的Quick Start.
就Spark目前的生态而言, 其对Python的支持仍不够完善, 切实际开发与Java/Scala有差异, 不利于演示, Scala我本人不熟, 所以后文中的示例均为Java版本, 这些示例的实际代码理论上都可以在安装Spark时附带的example中找到.
RDD模型
虽然RDD已经是一个过时的Api了, 他的地位逐渐被DataSet/DataFrame Api取代, 但说他作为Spark中的核心概念, 有助于理解后续内容, 因此这里也会讨论.
每个Spark应用都包含一个开发者编写的驱动程序(Driver Program), 包含入口main函数以在集群上执行各种并行操作. 在曾经, RDD是Spark提供的最主要的抽象概念, 代表了会被分区并行执行的数据集合, Spark应用的逻辑可以抽象为通过连接器(Connector)拉取数据, 转化为RDD, 执行高效的分布式并行计算, 并通过连接器输出计算结果. 连接器的交互对象可以是本地或HDFS上的文件, 如MySQL或MongoDB这样的数据库, 甚至是用于开发测试的Netcat Socket.
另一个Spark的抽象概念是共享变量(Shared Variable), 用以维持分布式计算的一致性状态. 分布式计算运行于不同节点上, 这超过了普通变量的作用域, 如果在计算逻辑中直接使用外部普通变量, 行为是未知的, 或者更准确的说, 只有在本地模拟集群时可能是正确的, 其余情况都是错误的, 因为变量的值会被序列化并拷贝至各个分区节点, 对分却节点上变量的操作并不会更新驱动程序中变量的值. 为了正确处理分布式计算的中间状态变量, Spark提供广播变量(Boardcast Variables)和累加器(Accumulator).
RDD提供的Api分为两种, 变换(Transformation)和动作(Action). 变换将已有的RDD转换为新的RDD, 而动作在RDD上执行计算并将值返回至驱动程序. 如Map是一个变换, 将RDD对应集合内的元素转换为新的元素, 而Reduce是一个动作, 汇总出结果并返回至驱动程序. 在Spark中, 所有的转换都是惰性的, 在动作执行前, 转换并不会真正的计算, 这种设计有助于节省开销和后续优化. 驱动程序会生成计算图并生成相应任务逻辑, 然后提交至Spark. 如果某一转换产生的中间结果会被多次利用, 那么他可以被缓存或持久化以避免重复计算.
与其他分布式系统一样, Spark在聚合过程中会引发数据重分布, 在Spark中这个过程称为排列(Shuffle), 由于涉及不同节点间的网络, 主存和磁盘IO, 因此会大幅影响Spark的执行性能.
这是一个简单的单词计数应用:
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
// 需要输入文件路径
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
// 构建Spark会话以获取上下文
SparkSession spark = SparkSession
.builder()
.appName("JavaWordCount")
.getOrCreate();
// 读取文本文件内容并转化为RDD
JavaRDD<String> lines = spark.read().textFile(args[0]).javaRDD();
// 按空隔和换行符将输入内容转换为拉平的单词数组
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
// 将单词映射为量化的二元组
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
// 按单词聚合, 累加每个单词的数量
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
// 收集结果至驱动程序并打印
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?,?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
spark.stop();
}
}DataSet/DataFrame和Spark SQL
Spark在1.6版本后引入新的DataSet/DataFrame接口以取代老旧的RDD, 在RDD的特性之上加强了对类型及其序列化方式的处理和SQL执行引擎的支持. DataFrame在Java和Scala中实际上等同于DataSet<Row>, 其中Row的含义为具有名称的列, 但列内值类型没有明确定义. DataFrame可以通过与RDD输入兼容的方式构建或直接从一个已有的RDD构建. 通过DataSet/DataFrame Api, 也使Spark可以将其计算模型进一步抽象为SQL语句的执行, 开发者可以结合使用SQL和DataFrame/DateSet来实现特定的业务逻辑.
下面的代码片段演示了DataFrame的使用:
Dataset<Row> df = spark.read().json("examples/src/main/resources/people.json");
// 展示
df.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// 树状打印自动检测的表结构
df.printSchema();
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// 通过Table Api进行聚合操作
df.select(col("name"), col("age").plus(1)).show();
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// 将DataFrame注册为临时视图
df.createOrReplaceTempView("people");
// 直接使用SQL基于SQL进行操作
Dataset<Row> sqlDF = spark.sql("SELECT * FROM people");
sqlDF.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+进一步, 我们可以将Row明确为一种特定的类型, 如DataSet<Peaple>. 与RDD传统的序列化方式不同, DataSet使用该类型特定的Encoder来序列化对象, 这些Encoder允许无需反序列化就在子节上执行如过滤, 排序和哈希等操作. 下面简单演示:
public static class Person implements Serializable {
private String name;
private int age;
// 省略Getter和Setter...
}
// 构建类实例
Person person = new Person();
person.setName("Andy");
person.setAge(32);
// 通过类信息构建Encoder
Encoder<Person> personEncoder = Encoders.bean(Person.class);
// 根据类实例创建DataSet并指定Encoder
Dataset<Person> javaBeanDS = spark.createDataset(
Collections.singletonList(person),
personEncoder
);
// 打印DataSet内容
javaBeanDS.show();
// +---+----+
// |age|name|
// +---+----+
// | 32|Andy|
// +---+----+
// 通过文件转化为DataSet并指定Encoder
String path = "examples/src/main/resources/people.json";
Dataset<Person> peopleDS = spark.read().json(path).as(personEncoder);
// 打印DataSet内容
peopleDS.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+Structured Streaming
前面我们总结了目前Spark在静态数据集批处理上的一些特性, 现在开始我们的主题, Spark Structured Streaming. Structured Streaming是Spark目前对流计算的解决方案, 需要强调, 在此之前Spark提供了Spark Streaming来实现流计算, 但与RDD相同, 它已经被新的Api取代, 因此下文讨论的都是Structured Streaming.
我在另一篇文章中讨论了流计算领域比较火热的Apache Flink, 并在文中介绍了流计算的一些核心概念, 重复部分下文将不会再提及.
概述
Structured Streaming是Spark在Spark SQL引擎之上构建的可扩展可容错的流计算引擎, 目标是让开发者能够像处理静态数据集一样处理动态的数据流, 并针对流计算, 提供了如窗口, Watermark快照, 结果多级别一致性保证等特性.
Spark持续的处理输入并更新计算结果, 其内部将流数据的计算视为对许多个Micro-Batch的批处理, 这与Flink这样遵循Kappa架构的流计算引擎有着相似的外表却不同本质. Spark能够以Micro-Batch处理方式实现100ms级别的端到端延迟及保证Exactly-Once级别的结果一致性. 在最新的Spark 2.3版本后, 增加了实验性的Continuous Processing特性, 借鉴了Flink的实现方式, 但为开发者封装为Spark的Api, 可以达到1ms级别的端到端延迟. 但Spark实现的Continuous Processing目前只能保证At-Least-Once级别的结果一致性, 与Flink仍有差距.
示例程序
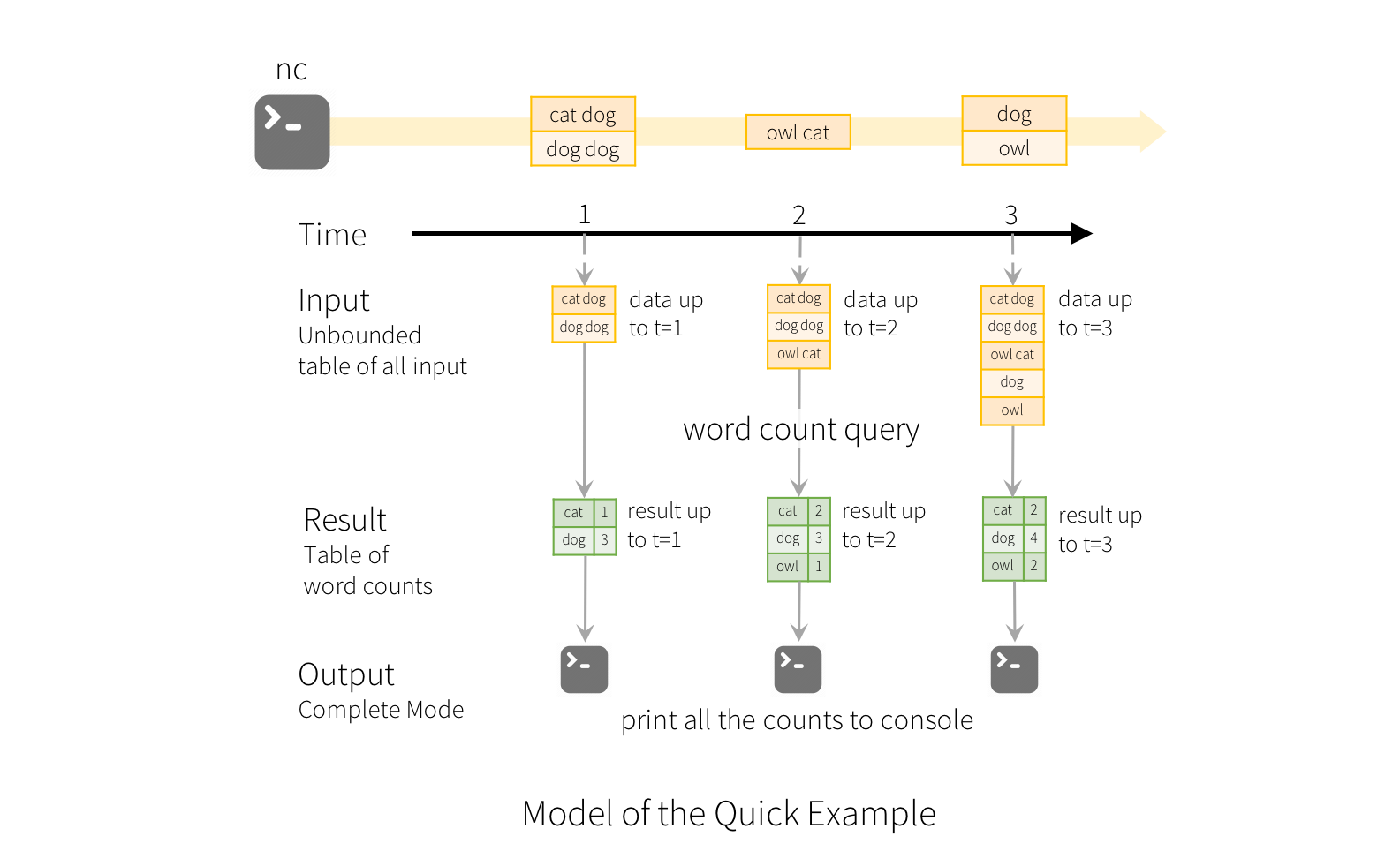
我们通过下面这个简单的程序展开对Spark Structured Streaming的讨论. 这个程序从一个Socket端口获取字符串数据作为输入, 简单统计单词数量, 并打印输出结果到控制台.
// 构建上下文
SparkSession spark = SparkSession
.builder()
.appName("JavaStructuredNetworkWordCount")
.getOrCreate();
// 以Socket端口为数据源,
// 将DataFrame Api中的read替换为readStream,
// 告知Spark我们将进行流计算.
Dataset<Row> lines = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
// 分词.
Dataset<String> words = lines
.as(Encoders.STRING())
.flatMap((FlatMapFunction<String, String>) x -> Arrays.asList(x.split(" ")).iterator(), Encoders.STRING());
// 汇总计算.
Dataset<Row> wordCounts = words.groupBy("value").count();
// 配置控制台为输出目标.
StreamingQuery query = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
// 等待手动结束.
query.awaitTermination();上面这个例子除了在输入和输出处的逻辑与批处理版本的WordCount有所不同, 计算部分几乎完全一致, 只是此处的DataSet对应于一个数据流而不是静态的数据集. 这种一致一方面得益于Spark在抽象封装方面做出的努力, 另一方面也因为我们的任务足够简单, 没有触及聚合操作在流计算上与批处理上的差异.
这段代码需要配合Netcat使用, 我们通过Netcat将命令行的输入转发至Socket.
启动我们的应用监听9999端口
...
将命令行输入转发至9999端口
nc -lk 9999与我在Flink文章中讨论过的一样, 流计算与对静态数据的批处理有着很多的不同, 需要考虑如何定义计算的范围, 如何保持状态, 如何在事件迟到, 重复的情况下保证计算结果的一致性, 如何在出现意外时容错等等. 我们接下来会以上面这个简单的例子为基础展开这些问题的讨论.
编程模型
基础
Structured Streaming的核心设计是将流数据视作动态增长的输入表(Input Table), 而将流计算实现为持续对其进行增量的批处理.
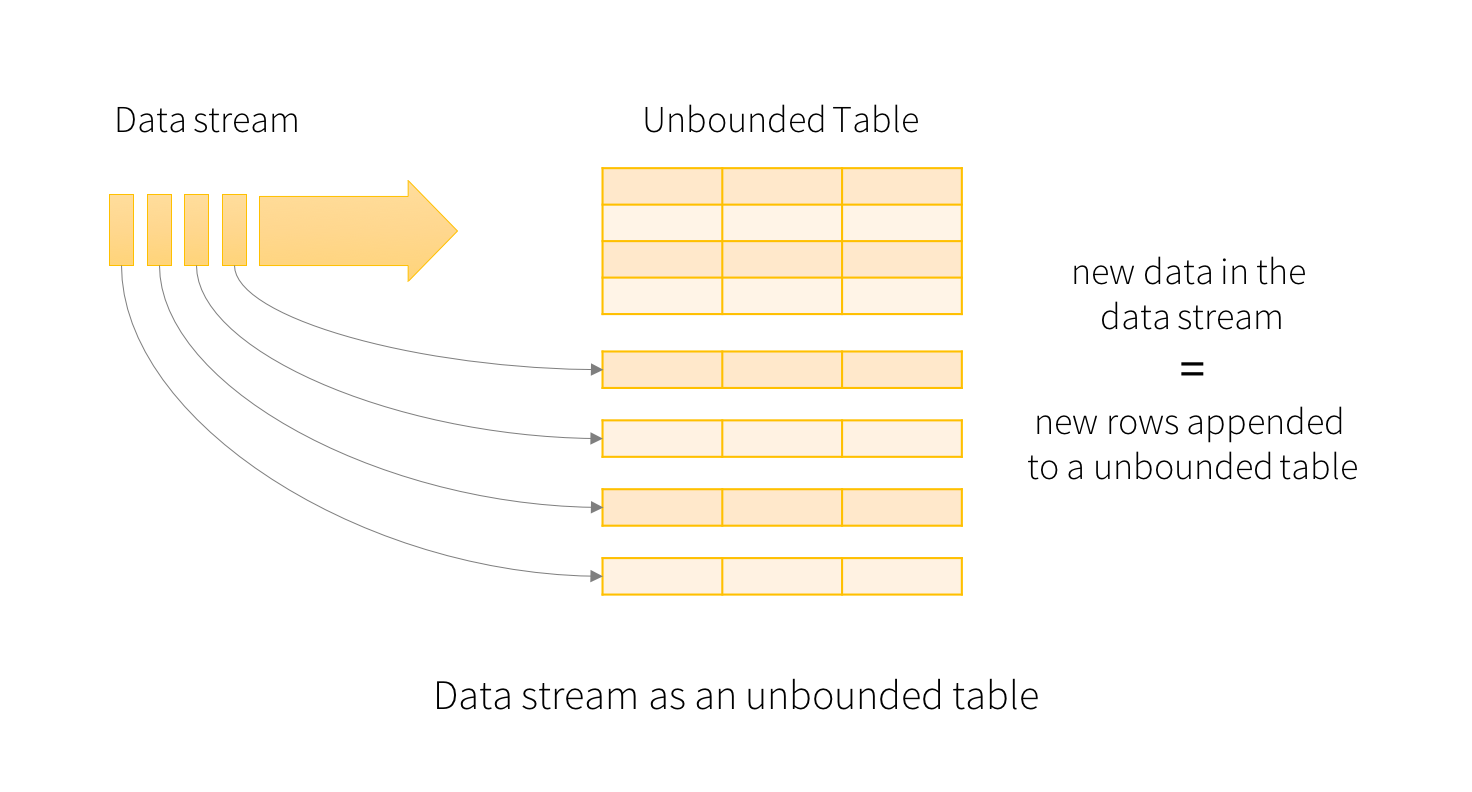
对这张输入表的计算会生成结果表(Result Table), 每次触发计算时(触发时机后文讨论), 新的行被追加至输入表末尾, Spark计算新的结果后更新结果表. 每当结果表被更新时, Spark会将结果表写出到我们定义的目标下游, 在我们的示例程序中, 将结果直接打印到了控制台, 在实际场景下, 他也许是Kafka实例.
在这种模型下, 开发者利用熟悉的DataFrame/DataSet接口处理流数据, 而由Spark在底层保证容错和数据一致性(At-Least-Once, At-Most-Once或Exactly-Once).
这幅图有一处容易造成误解的地方, 那就是实际上Spark并不会始终保留完整的输入表, 当Spark确认输入表中的前面一些行已经不再被后续更新状态的计算所需要时, 他们就会被丢弃.
开发者可以选择不同的输出模式(Output Mode), Spark会以不同的策略向外写出内容(当然, 不是随便选, 不同计算逻辑会对输出模式有不同的限制, 开发者只能做出有限的, 甚至仅有的选择):
- 完全模式(Complete Mode) - 将会写出完整的更新后的结果表.
- 追加模式(Append Mode) - 只会向外追加结果表, 因此只有当某一行的结果完全确定了之后, 他才会被写出. 保证已经写出的行正确性和无需修改.
- 更新模式(Update Mode) - 只写出结果表变更的部分. 如果计算不包括聚合操作, 则与追加模式等价.
处理事件时间和迟到数据
如在Flink介绍文章中提及的, 事件时间(Event Time)是指内嵌于数据本身的时间属性, 对很多应用而言, 这是开发者在时间维度上最关心的. 比如对于简道云而言, 用户何时提交数据, 往往比事件何时抵达Spark更有意义. 对Sturctured Streaming这种计算模型而言, 时间属性就是这张表中的某一列, 因此对时间维度的窗口支持就是在这一列上的分组和聚合操作, 因此也是通过DataSet相关的Api来完成的.
对迟到数据的处理也与事件时间有关, 这里只提一下, 具体内容会在后文讨论.
容错
Structured Streaming通过检查点(Checkpointing)和预写日志(Write-Ahead Logs)提供端到端Exactly-Once级别的一致性保证. 但要求上游是可通过偏移(Offset)重取的(Replayable), 如Kafka, 并且要求下游是幂等的, 如Kafka. 我总是用Kafka举例, 不是因为这些特性只支持Kafka, 而是因为对Kafka的支持是Spark内建的.
流处理下的DataSet/DataFrame Api
创建DataSet/DataFrame
作为流数据的输入源, 需要实现DataStreamReader接口. Spark内置了对4种输入源的支持, 下面简单列出.
| 源 | 是否支持容错 |
|---|---|
| 文件 | 是 |
| Socket(仅用于开发测试) | 否 |
| Kafka | 否 |
| Kafka | 是 |
这部分比较简单, 就不单独代码演示了…
基础操作 - Select, Project和Aggregate
这部分也比较简单, 因为和批处理下的DataSet/DataFrame Api的用法类似, 只是一些操作符如flatMap, 需要在编译时就了解类型信息, 此时可以参考前文对DataSet部分的演示.
下面的例子假设我们从IoT设备获取事件数据流:
public class DeviceData {
private String device;
private String deviceType;
private Double signal;
private java.sql.Date time;
...
// 省略Getter和Setter...
}
// 获取输入
Dataset<Row> df = ...;
// 声明类型信息
Dataset<DeviceData> ds = df.as(ExpressionEncoder.javaBean(DeviceData.class));
// 通过Untyped Api进行Select
df.select("device").where("signal > 10");
// 通过Typed Api进行Filter
ds.filter((FilterFunction<DeviceData>) value -> value.getSignal() > 10)
.map((MapFunction<DeviceData, String>) value -> value.getDevice(), Encoders.STRING());
// 通过Untyped Api获取每种设备类型的结果数据
df.groupBy("deviceType").count();
// 通过Typed Api分组汇总数据
ds.groupByKey((MapFunction<DeviceData, String>) value -> value.getDeviceType(), Encoders.STRING())
.agg(typed.avg((MapFunction<DeviceData, Double>) value -> value.getSignal()));
// 通过SQL进行查询
df.createOrReplaceTempView("updates");
spark.sql("select count(*) from updates");基于事件事件的窗口操作
如前文提及, Structured Streaming处理基于事件时间的窗口就像是基于某一事件维度列进行聚合操作. 以下内容仍以最前面所提到的单词计数为例, 假设现在流计算逻辑为每5分钟统计最近10分钟内的单词计数结果, 那么窗口将类似于12:00-12:10, 12:05-12:15, 12:10-12:20等等, 我们注意到如果一个事件, 它发生与12:07, 那么在这种情况下他满足两个时间窗口 - 12:00-12:10和12:05-12:15, 因此在结果中两个窗口的统计结果都应该因这一事件而增长. 那么流程大致如下图:
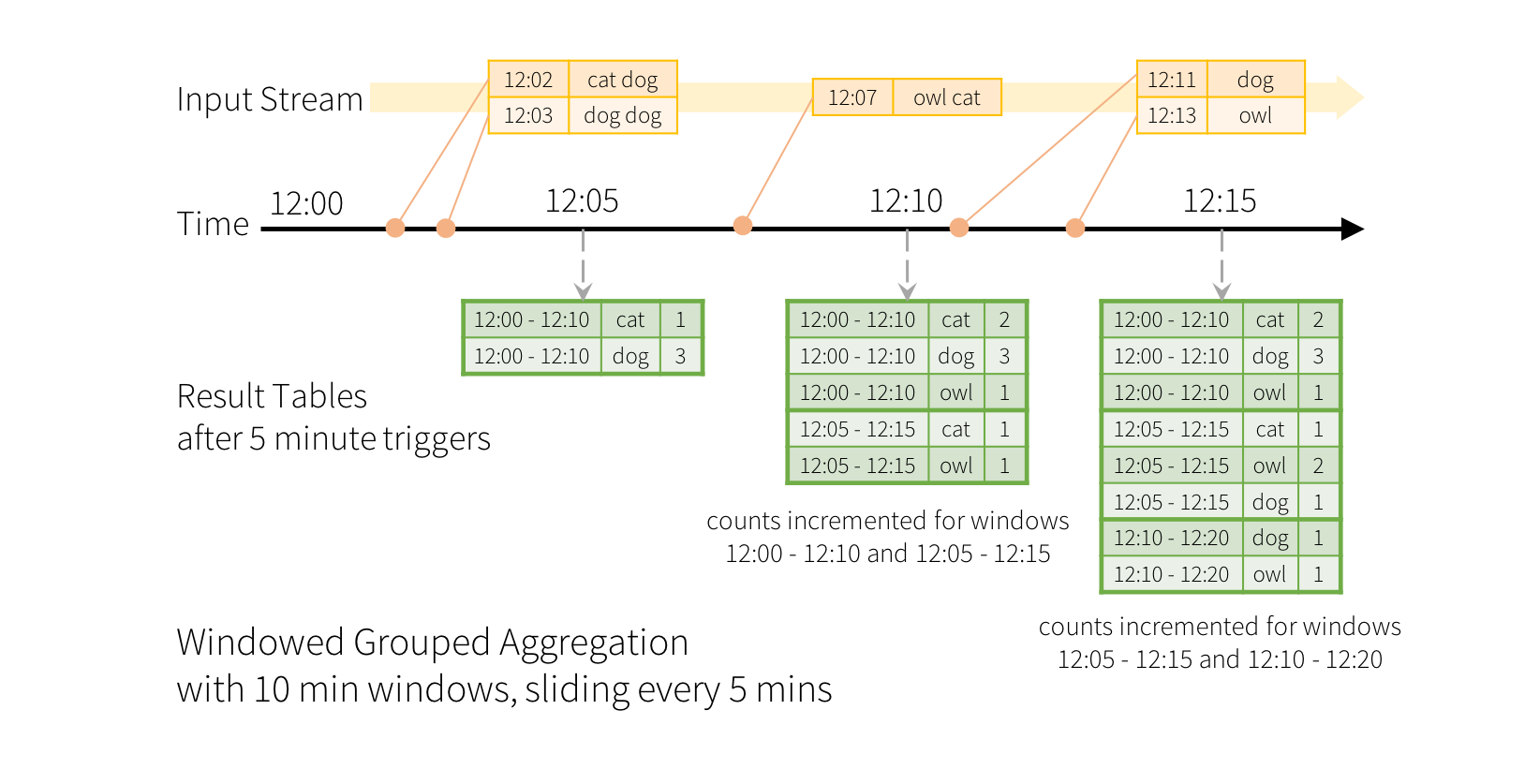
而对应的代码逻辑大致如下:
Dataset<Row> words = ...
Dataset<Row> windowedCounts = words.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word")
).count();代码很直观, 结合上图其逻辑很容易理解, 现在我们来加点复杂度.
迟到事件和Watermarking
实际环境中, 事件可能会和我们上班一样迟到, 举个例子, 我家里的树莓派12:04生成并发出的事件, 可能由于公司网不太好到12:11才经过小水管内网穿透抵达我在公司测试机上部署的Spark应用, 按照前文的逻辑, 他应当被更新到12:00-12:10范围的结果中. Structured Streaming可以容忍一定程度的数据迟到, 因此这一事件有可能被正确更新至结果表, 能够容忍的程度由开发者决定, 允许迟到的事件越久, 可能会给Spark带来更大的开销(因为要长时间保留前面的输入表和状态以供迟到数据参与计算)和结果集输出更大的延迟(如果为追加模式输出). 下图简单展示迟到数据的处理:
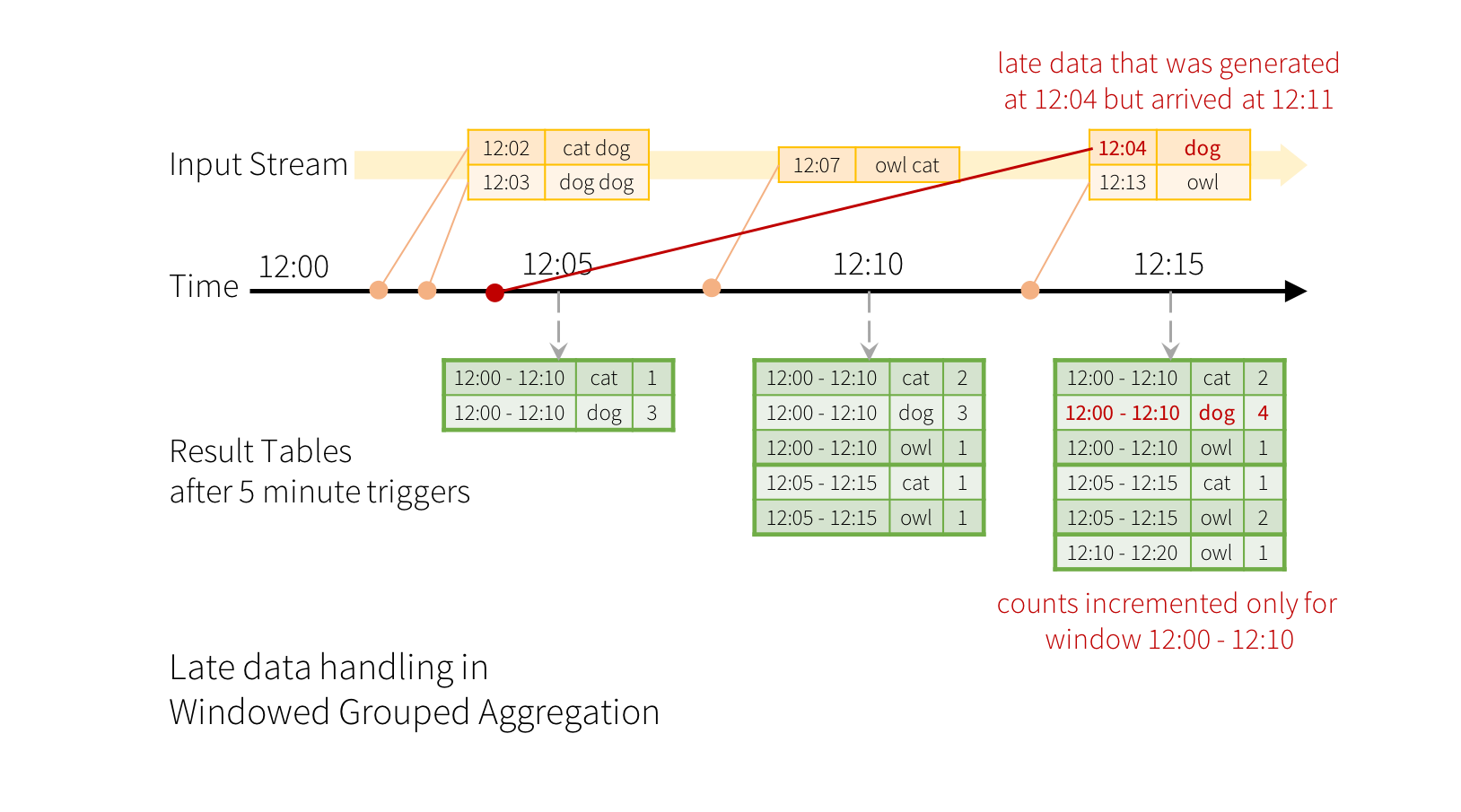
为了理解Structured Streaming究竟如何处理迟到数据和决定哪些输入和状态已经可以被丢弃, 我们来介绍Spark 2.1引入的Watermaking概念.
Watermarking是Spark用来跟踪当前数据流事件时间状态和确定合适放弃指定事件的迟到数据, 清理不再需要的历史状态并写出确定结果的机制. 开发者在操作上能够容忍最晚多久的阈值, 换言之, 对于指定的窗口结束时间T, Structured Streaming引擎维护流计算状态并允许迟到事件更新此状态直到max event time seen by the engine - late threshold > T, 再晚的事件就讲被丢弃. 我们来看示例:
Dataset<Row> words = ...
// 窗口规则与前文所述一致
Dataset<Row> windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word"))
.count();我们在对timestamp列的操作上定义了阈值为10分钟的Watermark, 如果输出为更新模式(Update Mode, 前文已解释), 那么以窗口内最后正常到达数据的事件时间为基准, 允许迟到时间在10分钟内的数据更新结果表中的数据. 如下图:
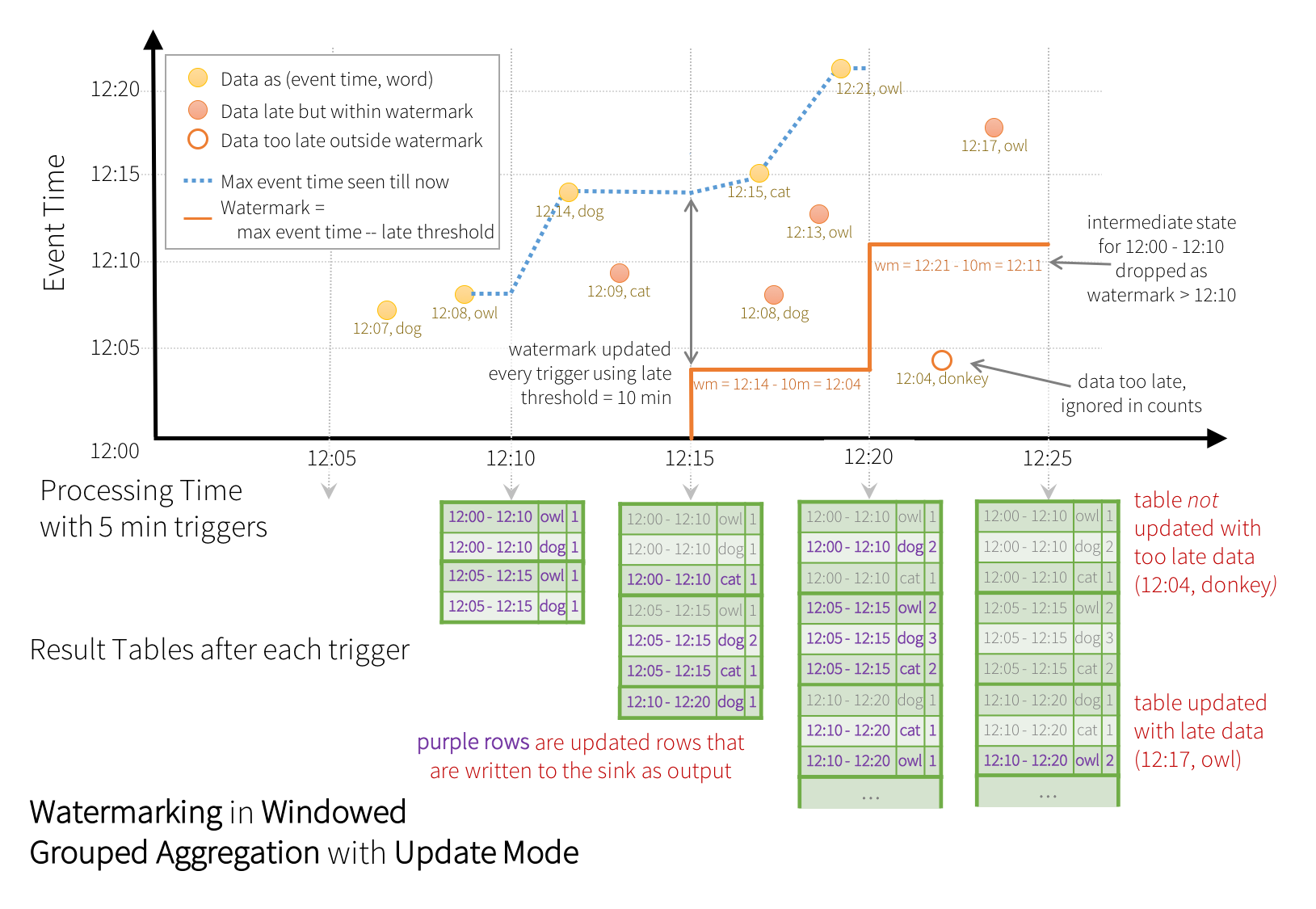
上图中, 蓝色的线为Spark从数据流中得到的最新数据事件时间线, 红色的线则是每次触发新窗口更新的Watermark线, 结果表中的紫色行为当次更新内容. 举例说明, 当(12:14, dog)到达的时候, Spark按照规则将Watermark置为12:04, 当迟到数据(12:09, cat)的事件时间在当前Watermark之后, Spark保留的输入表和状态信息仍有能力对其进行处理, 该迟到数据属于窗口12:00-12:10和12:05-12:15, 因此Spark将其更新至结果表中. 但在下一次窗口计算触发时, Watermark被更新为12:11, 因此更新窗口12:00-12:10计算结果的必要资源已被清理, 随后到达的(12:04, donkey)就会因为迟到过久而被丢弃.
由于输出表中的行可能会因为迟到数据而更新, 因此该行何时可以被写出也取决于前文提及的出模式, 比如有些对文件的写出接口不支持对已写内容进行更新, 那么就可以使用追加模式(Append Mode)来处理他们.
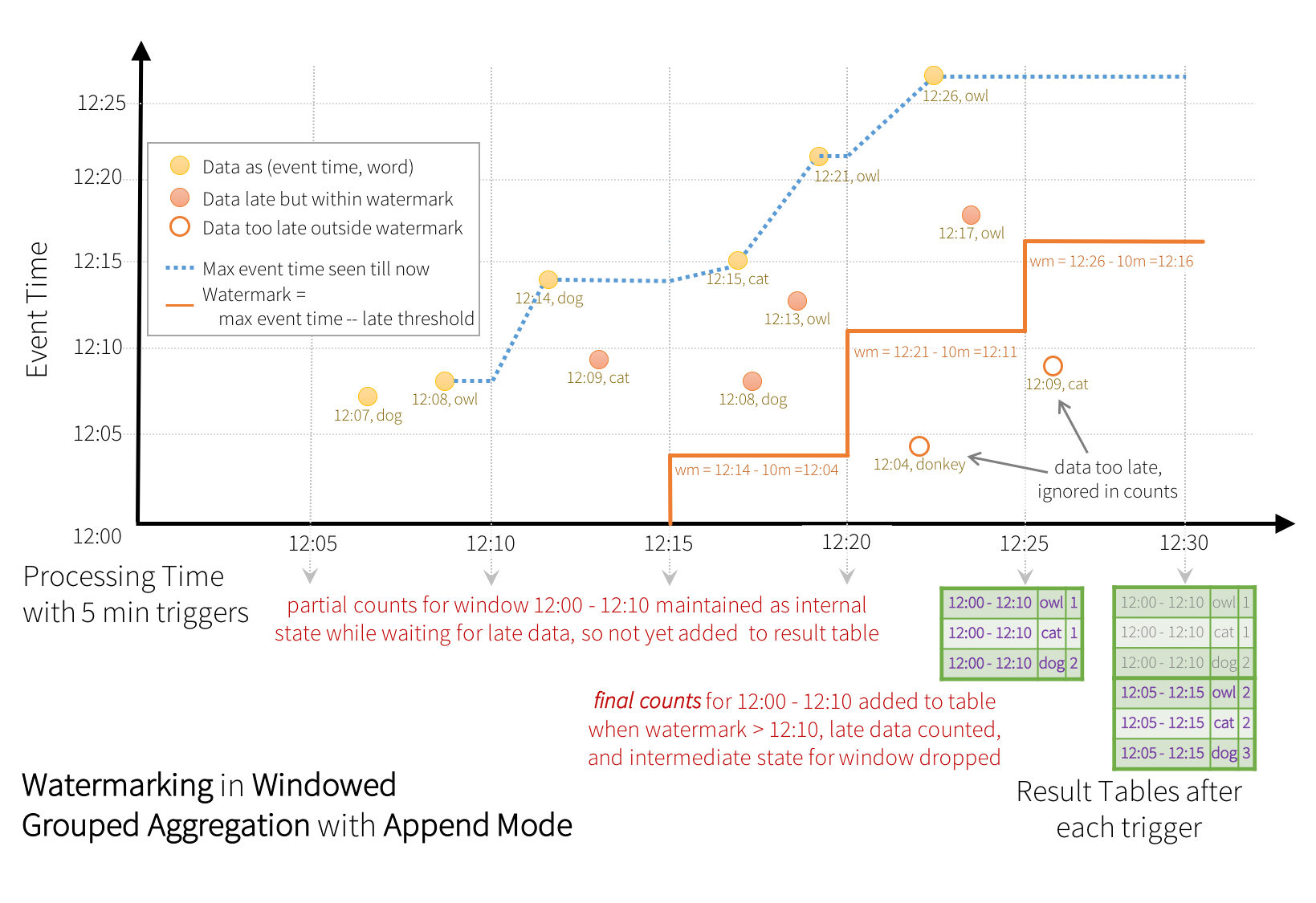
可以看到, 在追加模式下, 结果表中的行直到完全确定后才会被写出, 因此实际写出发生的比更新模式下更晚. 举例来说, 12:00-12:10窗口的聚合结果直到12:20时由于Watermark值被更新为12:11时才写出.
那么我们总结一下Structured Streaming在满足哪些条件下才会清理不再需要的状态(仅适应当前版本区间, 2.1.1-2.4.4, Spark文档中提及这些条件可能在未来的版本中改变):
- 输出模式必须为追加或更新. 完全模式(Complete Mode)需要保留全部状态信息.
- 必须有时间维度的列, 并在这一列上应用窗口聚合逻辑.
- 必须在该时间维度列上设置Watermark规则.
- Watermark规则的设置必须在聚合操作之前.
我们再明确一下Watermark的语意和一致性保证:
- 一个“2 hou rs”的Watermark保证Spark不会丢弃任何2小时内的数据, 因此在最新数据事件事件之前两小时内的数据都会被更新至聚合结果.
- 注意上一条的措辞, 这个保证是单向的, Spark并不保证延迟超出2小时的数据一定不会被处理, 只能说超时越久的数据, 参与计算的可能性越小.
这里提一下, 如果DataSet/DataFrame下的数据是静态数据集, 那么通过Watermark Api的设置将会被忽略.
Join 操作
Structured Streaming支持将流与静态数据集之间, 流与流之间的Join. 与流上的聚合操作类似, 流参与的Join是增量生成的. 不同的Join存在各自的限制. 我们下面展开讨论. 同样的, 下述讨论仅针对当前版本.
Stream-Static Join
Spark在2.0之后支持流与静态数据集间的Join, 包括Inner Join和特定类型的Outer Join(具体限制在后面的表格中一起总结), 下面是简单的代码示例:
Dataset<Row> staticDf = spark.read(). ...;
Dataset<Row> streamingDf = spark.readStream(). ...;
// Inner Join
streamingDf.join(staticDf, "type");
// Right Outer Join
streamingDf.join(staticDf, "type", "right_join");Stream-Stream Join
Spark在2.3之后增加了流与流之间的Join, 这种Join的挑战在于, 在任意一个时间点, Spark并不完整保有两个流对应的输入表. 因为某一张表中的一行可能与另一张表中已经到达或还未到达的迟到数据相关联, 所以将他们关联起来是很困难的. Spark必须能够在可控的范围下将必要的历史状态信息进行保留, 并能正确处理迟到数据, 以最终得到一致的Join结果. 我们需要进一步细分Join的类型来深入讨论.
带有可选的Watermark的Inner Join
Structured Streaming支持任意类型列的Inner Join. 但会存在一个问题, 由于Spark必须保有全部历史数据以计算Join结果, 随着数据的到达, 流状态会不断膨胀, 这对于无界流来说是不能接受的. 为了避免这种情况, 开发者必须设法定义额外的Join条件, 保证老数据不会与新数据关联, 来让Spark安全的清理他们. 换言之, 需要做以下额外操作:
- 在两个流上定义Watermark, 告知Spark如何容忍迟到数据.
- 在两个流上对事件事件进行限制, 告知Spark可以清理多久之前的历史数据, 如:
- 基于时间范围Join, 如
...JOIN ON leftTime BETWEEN rightTime AND rightTime + INTERVAL 1 HOUR. - 基于事件窗口Join, 如
...JOIN ON leftTimeWindow = rightTimeWindow.
- 基于时间范围Join, 如
举个实际的例子, 假设我们要把广告展示时间表内的数据与广告被点击时间表内的数据做Join来的到哪些展现最终引导了用户的点击行为, 很明显在展现后的某个时间区间内的点击才应当被关联, 因此我们将建立以下查询:
- Watermark: 告知Spark, 展示事件数据最多迟到2小时, 点击事件数据最多迟到3小时. 正如标题指出的, 这一限制不是必须的.
- 事件事件范围条件: 告知Spark, 在展示时间后的0到1小时内的点击时间才应当被关联.
代码演示大致如下:
Dataset<Row> impressions = spark.readStream(). ...
Dataset<Row> clicks = spark.readStream(). ...
// 在流上添加Watermark
Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
// 在Join上添加时间限制
impressionsWithWatermark.join(
clicksWithWatermark,
expr(
"clickAdId = impressionAdId AND " +
"clickTime >= impressionTime AND " +
"clickTime <= impressionTime + interval 1 hour ")
);Watermark在此种场景下提供的语意保证与前文中已提及的一致, 不再重复展开说明.
带有Watermark的Outer Join
在Inner Join中Watermark限制是可选的, 但在Left Outer Join和Right Outer Join中却是必须的, 这是因为Outer Join会在无匹配时产生NULL, Spark必须准确知道到什么时间这一行久一定不会与未来到达的任何数据相关联, 正是依靠Watermark对迟到行为给出限制和保证. 所以Outer Join的代码会和上文中的示例很相似, 只是待有额外的参数:
impressionsWithWatermark.join(
clicksWithWatermark,
expr(
"clickAdId = impressionAdId AND " +
"clickTime >= impressionTime AND " +
"clickTime <= impressionTime + interval 1 hour "),
// 可以是"inner", "leftOuter"和"rightOuter"
"leftOuter"
);理解Spark如何生成Outer Join的结果很重要, 我们在此明确:
- Spark必须根据Watermark和Join上的时间条件, 在一定延迟之后才能确定Outer Join的结果和是否产生NULL值.
- 目前的Micro-Batch实现中, Watermark会在Micro-Batch执行后计算并更新, 状态清理和结果写出则发生在下一次Micro-Batch计算前. 由于Micro-Batch的计算只会在新数据到来时才会触发, 因此如果一直没有新数据到达, 那么结果写出会被延迟.
总结
| Left Input | :-: | Join类型 | 是否支持 |
|---|---|---|---|
| Static | Static | 所有 | 支持 |
| Stream | Static | Inner | 支持, 无状态 |
| Left Outer | 支持, 无状态 | ||
| Right Outer | 不支持 | ||
| Full Outer | 不支持 | ||
| Static | Stream | Inner | 支持, 无状态 |
| Left Outer | 不支持 | ||
| Righter Outer | 支持, 无状态 | ||
| Full Outer | 不支持 | ||
| Stream | Stream | Inner | 支持, Watermark和事件时间限制条件是可选的 |
| Left Outer | 部分支持, Watermark和事件时间限制条件是必须的 | ||
| Right Outer | 部分支持, Watermark和事件时间限制条件是必须的 | ||
| Full Outer | 不支持 |
额外说明:
- Join可以级联, 即
df1.join(df2, ...).join(df3, ...).join(df4, ....)是合法的. - 截止Spark2.4, 流Join结果的写出仅支持追加模式.
- 截止Spark2.4, 在Join之前不能使用Non-Map-Like聚合.
流去重
与静态数据集一样, 开发者可以通过定义Unique Key列来对数据进行去重. Spark会保有必要的状态信息来完成这一任务. 与聚合一样, 开发者可以选择使用或不使用Watermark.
- 使用Watermark - 此时对重复数据的最晚到达时间提出了限制, 因此Spark能够尽早的清理一些不再必要的中间状态.
- 不使用Watermark - 由于对重复数据的检测不存在边界, Spark将不得不保留其所需的全部状态信息.
代码示例:
Dataset<Row> streamingDf = spark.readStream(). ...;
// 不使用Watermark, 通过guid列去重.
streamingDf.dropDuplicates("guid");
// 使用Watermark, 基于事件时间通过guid列去重.
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime");任意状态操作
许多使用场景下, Structured Streaming提供的抽象仍不能满足我们的计算模型, 开发者希望能够以自己的方式追踪数据流, 并以自定义的数据结构维持计算中间状态. 在Spark 2.2之后, Spark提供了mapGroupsWithState和特性更多的flatMapGroupsWithState来允许开发者对聚合分组后的DataSet运行自定义代码来更新自定义状态数据结构, 更多细节可以查看Api文档和示例, 这里不再展开讨论.
目前仍不受支持的操作
总结一下目前版本的Spark在Structured Streaming下不被支持的DataFrame/DataSet Api:
- 不支持链式聚合操作.
- 不支持Limit和First N逻辑.
- 只支持聚合后的, 以完全模式作为输出的Sort.
- 前文整理过的一些场景下的Join.
此外, 有些Api会直接在DataFrame/DataSet对应的部分数据集上执行, 因此通常是没有意义的:
- count() -应当被替换为
ds.groupBy(...).count(). - foreach() - 应该替换为
ds.writeStream.foreach(...). - show() - 应该被替换为使用中断槽.
某些不支持的操作在未来的Spark中可能被解决并支持, 但有些是从逻辑上就难以实现的, 比如对无界数据流的排序.
Continuous Processing
Continuous Processing是Spark 2.3引入的新的实验性的流执行模式, 他将端到端延时降低至了1ms级别并保证At-Least-Once级别的一致性语意. 这与Flink的处理方式类似, 但Flink能够提供Exactly-Once级别的一致性保证.
下面这段代码简单做一个示例:
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
// 下面这行是唯一的改变
.trigger(Trigger.Continuous("1 second"))
.start();1秒的检查点配置指出Spark应当每秒记录流执行状态. Continuous Processing模式下的检查点记录与Micro-Batch模式下的检查点兼容, 因此你可以停止应用更换Triger并重新启动来切换至Micro-Batch, 增加延迟但带来Exactly-Once级别的机制性保证, 反之亦然.
支持程度
截止Spark 2.4, Continuous Processing仅支持:
- Operation: 只有Map-Like的DataSet/DataFrame操作被支持, 也就是Projection(select, map, flatMap和mapPartitions等)和Selection(where和filter等).
- 源(上游):
- Kafka: 全部特性.
- Rate Souarce: 部分特性, 用于开发测试.
- 槽(下游):
- Kafka: 全部特性.
- 内存: 用于开发测试.
- 终端: 用于开发测试.
注意事项
- Continuous Processing会创建多个长时间运行的任务来持续的读取源数据, 计算并写出到槽. 任务的数量取决于从源数据读取时创建多少个分区. 因此, 在执行Continuous Processing前必须确保集群拥有足够的CPU核心资源. 举个例子, 如果从Kafka Topic读取10个分区的数据数据, 集群必须至少剩余10个核心.
- 停止Continuous Processing会报一些Task意外停止的错误, 可以直接忽略.
- 没有出错自动重试机制, 如果出错了, 需要手动从上一个检查点重新启动.
可以看出, Structured Streaming的这个全新的计算模式还非常不成熟, 完全无法投入生产环境使用.
总结
Spark试图通过Structured Streaming让开发者使用与静态数据集批处理类似的接口完成流计算任务而无需关心底层数据流的特性, 他也是这样宣传的, 但实际上到目前为止(Spark 2.4.4), Structured Streaming并没有比其他流计算引擎做的更出色, 他可能是在和Storm做对比, 但Spark提供的流计算接口虽然与批处理接口形式类似, 足够抽象看起来易于上手, 但存在着各式各样需要小心处理的限制. 虽然相比Flink而言我并不特别看好目前的Structured Streaming, 但Structured Streaming尝试通过Micro-Batch的方式处理流数据过程中很多设计思想仍是值得借鉴和学习的, 并且在最新的Spark中, 我们也看到了Continuous Processing这样的, 尝试从Flink的设计中获取灵感的发展方向, Structured Streamming在将来势必会变的更加完善和可用.
许可协议: CC BY-NC-SA 4.0
本文链接:https://blog.angelmsger.com/Spark的流计算方案-Structure-Streaming/