查找附近的人: GeoHash算法
GeoHash是一种快速查找附近单位的算法.
GeoHash是什么
前段时间研究MongoDB, 发现MongoDB存在一种2d索引和一种2dsphere索引, 基于这两种索引可以对存储的数据进行进行一些Geo查询, 比如查找附近的餐馆, 地铁站等等, 很有意思也很方便. 之后就想知道背后的原理.
如果交给我这种过于相信机器计算能力的人, 就需要遍历所有的餐馆, 网吧和地铁站, 然后计算两点间的距离, 再将距离小于一定阈值的点罗列出来. 地铁站还好, 但是每个地方的餐馆, 网吧数量就很多了, 这种朴素算法的效率无法满足需求. 虽然我们可以进一步缩小范围, 毕竟我们已经知道了某一个要查找的点, 不过这种遍历所有点后一顿狂算的方式还是不怎么优雅.
说道快速查找与利用条件过滤, 不难联想到一个东西, 那就是索引. 我曾在[说说MySQL存储引擎, 索引及基本优化策略](../说说MySQL存储引擎, 索引及基本优化策略)和利用相似哈希判断文本近似程度中提到, 对于长而杂乱的字符串或结构复杂数据, 我们可以通过某种编码方式, 将其对应为易于索引的短串, 就可以比较方便的进行比对和查找. 地理位置信息与此类似, 经纬度座标数据也具有上述特点, 我们要想办法为他建立索引, 使地理位置相近的点索引值也不会相差太多, 方便我们快速某一个点查找附近的其他点. GeoHash正是这样一种算法.
GeoHash的实现原理
首先要说明的是, 本文是我阅读了GeoHash核心原理解析后的总结, 原文写的很好, 也很直观, 推荐阅读. 本文接下来的部分也基本是原文的复述.
GeoHash算法的基本思想是将某一个区域映射为一个字符串, 这个字符串有一些特点. 比如对于区域的划分, 可大可小, 大区域可再分为小区域. 对于有这样类似父子关系的区域, 小区域与大区域应当有相同的前缀, 而小区域对应的串应当大区域对应的串的基础上更长一些, 多出的一些用以描述小区域相对于大区域的位置. 也就是说, 我们把所有要考虑的地方看成一个最大的区域, 然后开始划分, 在划分的结果中再划分, 并不断映射为字符串, 字符串越长, 地理位置越精确.
所以我们始终是在以区域讨论问题, 而不是某个具体的座标点. 不过其实很多应用并不需要精确的位置信息, 而且这样做有以下两方面的好处:
- 利于保护用户隐私, 该区域内所有用户得到的索引值是相同的.
- 易于缓存, 以区域作为缓存对象是更加高效的, 同一区域内的请求可以共享结果, 我们不能总是期待用户站在同一个精确点上发出请求.
我们根据索引后的字符串前缀来匹配POI(Point of Interest, 感兴趣的点, 比如前文所述查找附近的餐馆和地铁站)信息, 通过前缀长度不同控制粒度(范围), 而相邻区域拥有相同的前缀, 因为他们同属与同一个更大的区域. 这样的查找是十分高效的.
举例
我们来讨论点更实际的.
我们知道地球的经度范围为[-180, 180), 纬度范围为[-90, 90]. 现在我们实用二分法, 对经度和纬度进行划分, 如果经纬度在划分后的左半区域, 则写为0, 右半区域则写为1. 比如对于给定的经纬度(116.389550, 39.928167), 我们得到如下序列: (1101001011, 1011100011). 然后我们将两个二进制串合并, 奇数放纬度, 偶数放经度, 则得到新串11100111010010001111. 之后对此串进行Base32编码, 就得到了最后的编码wx4g. Base32编码是一个可逆的过程, 我们通过以上操作的逆操作可以得到某一编码所对应的经纬度范围.
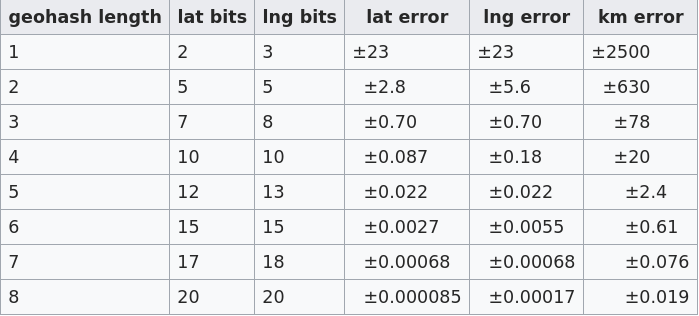
根据维基百科的信息, 当编码长度为8时, 精度大约能够达到19米, 当编码长度达到9时就可以精确到2米了.
还有一个需要在实际实用中注意的点. 比如对应于某一区域内靠近边缘的点, 位于相邻区域内的某些目标肯能比本区域内的目标更加接近, 如果只在当前区域内查找则会得出一些不是非常理想的结果, 对于这钟情况, 我们通常会选择与当前区域相邻的其他8个区域参与计算.
参考资料
许可协议: CC BY-NC-SA 4.0
本文链接:https://blog.angelmsger.com/查找附近的人:GeoHash算法/