开源Serverless项目概览
前段时间一直比较忙, 没有更新博客. 这几天由于工作需要, 简单了解了目前几个比较流行的开源Serverless项目, 主要是想看看大体的设计思路和最终的代码执行方式, 刚好写一篇文章作为记录.
概述
FaaS即Function as a Service, 函数即服务, 意指用户仅需提供业务逻辑(函数代码), 平台提供弹性算力支持, 用户按量付费. 我最早接触这个概念是几年前AWS推出Lambda服务的时候, 因为从原理上其实现必然会带来很多不必要的性能开销, 所以当时觉得有点扯. 不过如今随着Kubernetes的普及, 算力价格的下降, 国内的云平台也开始宣传起无服务器架构的概念了, 并且提供可观的免费额度, 让这一思路成为了特定场景的备选方案之一. 下图是OpenFaaS作者于2019年上传至Youtube的对OpenFaaS的介绍演讲中提到的他关于Serverless所处阶段的理解:

现在什么都可以即服务了, 前段时间阅读xCloud平台介绍的时候, 他们称之为GaaS, Games as a Service.
除了AWS的Lambda, 国内云平台如阿里云, 腾讯云提供的函数计算服务外, FaaS自然也不缺少开源实现. 目前比较有影响力的主要有4个, OpenFaaS, Kubeless, Knative和Nuclio, 我简单了解了一下这些项目的大体的设计思路和最终的代码执行方式.
开源实现
OpenFaaS
OpenFaaS是三个项目中影响力最大的(至少从GitHub Star的数量上), 也是唯一一个不限于Kubernetes平台的FaaS实现. 项目发起的时间比较早, 初版基于Docker Swarm, 但随着Kubernetes在容器编排领域优势的日趋明显, 项目将底层实现抽象出FaaS Provider接口并提供了Kubernetes实现.
基本实现
OpenFaaS将自己的技术架构称为PLONK, 即Prometheus, Linkerd, OpenFaaS, Nats和Kubernetes. OpenFaaS的主要贡献者Alex在Youtube上分享了他的一次演讲, 介绍FaaS的相关概念和OpenFaaS的基本实现, 不过讲解的比较浅, 下面是我结合他的演讲及OpenFaaS的文档进行的一些整理, 如图是其基础架构:
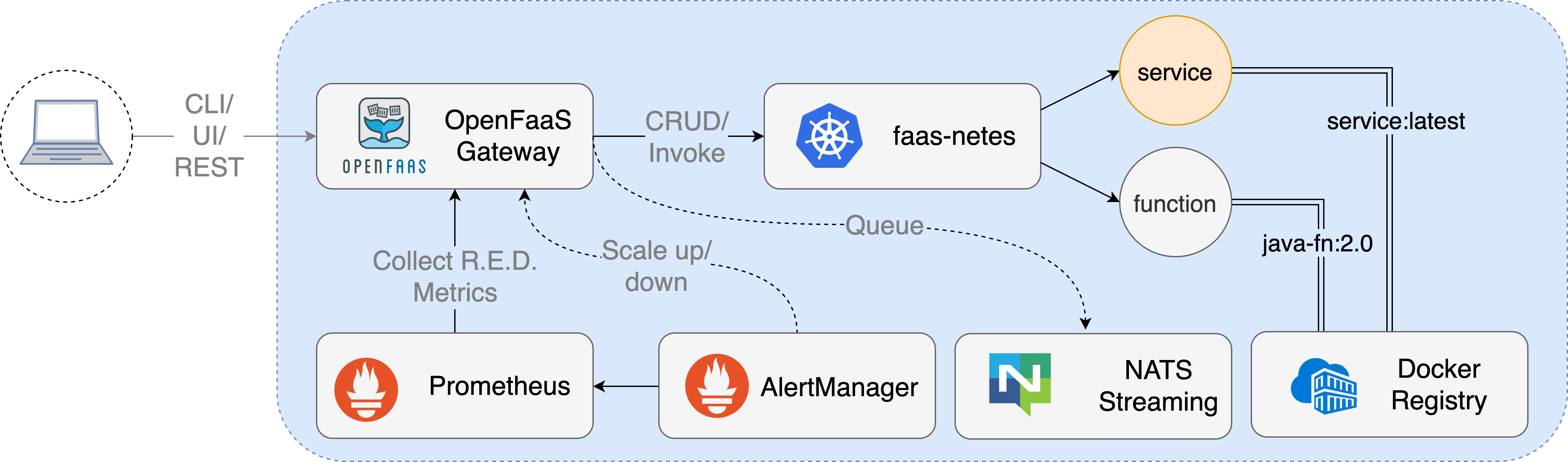
函数挂载在某个路由上, 如/function/NAME或/async-function/NAME, 外部通过Gateway以RESTful API的方式访问函数. 其各组件职责如下:
- Prometheus: 监控由Gateway暴露的函数的Metrics, 当满足某些条件时由AlertManager触发Auto Scaling, 即函数背后的容器实例的弹性伸缩.
- Linkerd: 一个可选的Service Mesh组件, 实现集群内点到点TLS, 流量观测和分发等特性.
- OpenFaaS: 各个语言下的函数模板, 代码封装及运行时实现, 指标的采集, 监控和响应, 与Docker Swarm, Kubernetes等Provider的集成适配.
- Nats: Nats是一个云原生的分布式队列实现. 在OpenFaaS中的职责是流控和处理函数异步执行.
- Kubernetes: 底层容器编排逻辑实现, 包括弹性伸缩, 负载均衡和滚动更新等Kubernetes自身提供的特性.
当通过OpenFaaS的客户端(CLI/UI Dashboard/RESTful API)创建函数后, OpenFaaS会将函数体包裹于对应运行时(如Node.js)的上下文中, 添加守护进程(即后文提及的Watchdog), 打包镜像. 当函数被调用时, 在同步的情况下, 请求从Gateway经由Kubernetes内部最终转发至容器中的守护进程, 再由守护进程转发至实际执行函数代码的子进程, 子进程执行函数后将输出原路返回; 在异步的情况下, 请求会被持久化至Nats队列中, 并在实际执行后通过CallbackUrl的方式返回至调用者.
代码执行
前文所述的过程中, 实际负责运行代码的是守护进程Watchdog. 随着项目的推进, OpenFaaS到目前实现过两版Watchdog, 分别是早期的Classic Watchdog和后来的Of-Watchdog. Classic Watchdog非常简单, 我截取了一部分核心代码如下:
// handler.go
func pipeRequest(config *WatchdogConfig, w http.ResponseWriter, r *http.Request, method string) {
startTime := time.Now()
parts := strings.Split(config.faasProcess, " ")
// ... 省略参数处理
targetCmd := exec.Command(parts[0], parts[1:]...)
// ... 省略环境变量处理
writer, _ := targetCmd.StdinPipe()
var out []byte
var err error
var requestBody []byte
// 并发 Barrier
var wg sync.WaitGroup
wgCount := 2
// ... 省略 fork 错误处理
wg.Add(wgCount)
var timer *time.Timer
if config.execTimeout > 0*time.Second {
// 添加超时杀死子进程逻辑
timer = time.AfterFunc(config.execTimeout, func() {
log.Printf("Killing process: %s\n", config.faasProcess)
if targetCmd != nil && targetCmd.Process != nil {
ri.headerWritten = true
w.WriteHeader(http.StatusRequestTimeout)
w.Write([]byte("Killed process.\n"))
val := targetCmd.Process.Kill()
if val != nil {
log.Printf("Killed process: %s - error %s\n", config.faasProcess, val.Error())
}
}
})
}
// 通过 STDIN 将参数传递至子进程
go func() {
defer wg.Done()
writer.Write(requestBody)
writer.Close()
}()
if config.combineOutput {
// 合并 STDOUT 与 STDERR 输出
go func() {
defer wg.Done()
out, err = targetCmd.CombinedOutput()
}()
} else {
// 拆分 STDOUT 与 STDERR 输出
go func() {
var b bytes.Buffer
targetCmd.Stderr = &b
defer wg.Done()
out, err = targetCmd.Output()
if b.Len() > 0 {
log.Printf("stderr: %s", b.Bytes())
}
b.Reset()
}()
}
wg.Wait()
// 如果子进程已经执行完毕但计时器尚未执行, 则清理计时器
if timer != nil {
timer.Stop()
}
// ... 省略进程执行失败处理逻辑
var bytesWritten string
if config.writeDebug == true {
os.Stdout.Write(out)
} else {
bytesWritten = fmt.Sprintf("Wrote %d Bytes", len(out))
}
if len(config.contentType) > 0 {
w.Header().Set("Content-Type", config.contentType)
} else {
// Match content-type of caller if no override specified.
clientContentType := r.Header.Get("Content-Type")
if len(clientContentType) > 0 {
w.Header().Set("Content-Type", clientContentType)
}
}
// 耗时统计
execDuration := time.Since(startTime).Seconds()
if ri.headerWritten == false {
w.Header().Set("X-Duration-Seconds", fmt.Sprintf("%f", execDuration))
ri.headerWritten = true
w.WriteHeader(200)
w.Write(out)
}
// ... 省略日志输出
}通过代码可以看出, Classic Watchdog在接收Http请求后, 直接以子进程的的方式执行了用户代码, 并没有太多的逻辑处理. 其缺陷可想而知, 由于每个请求都是独立的子进程, 因此如数据库连接, 本地缓存和通用环境(如Express)等都无法在多个请求见复用, 必然导致依托于此逻辑实现的函数计算最终性能较差. Of-Watchdog正是为了解决这一问题做出的改进版本, 目标在于Keep Warm和多次响应. 其提供多种模式, 大致结构如下:
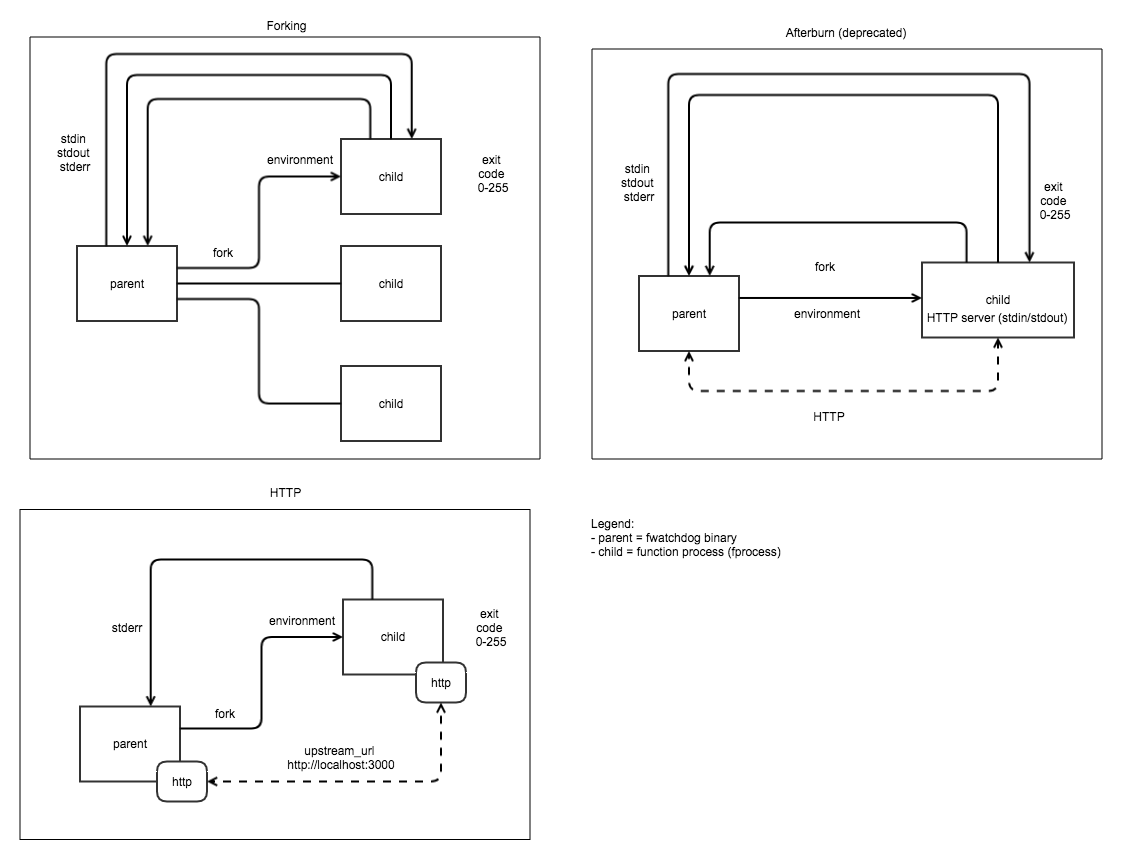
以Http模式举例, Of-Watchdog实际上在原本代码逻辑外又包装了一层Web Server, 以便函数体能够通过全局变量的方式保留一些可能会被多次利用的实例或资源.
弹性伸缩
对于函数容器实例的弹性伸缩, OpenFaaS目前有两种解决方案:
- 通过Prometheus和AlertManager基于规则(如函数响应时间)增加或减少副本的数量, 配合FaaS-Idler可以让函数实例数量在0~`com.openfaas.scale.max`间浮动.
- 通过Kubernetes HPA基于Pod CPU/Memory指标自动增加或减少副本的数量.
Kubeless
Kubeless, 从名字就可以看出这是一个依托于Kubernetes的实现.
Kubeless的实现基于Kubernetes的多项特性:
通过CRD实现了抽象的Function类型.
apiVersion: kubeless.io/v1beta1 kind: Function metadata: labels: created-by: kubeless function: get-python // ... 省略 Kubeless 其他元信息 spec: checksum: sha256:d251999dcbfdeccec385606fd0aec385b214cfc74ede8b6c9e47af71728f6e9a deployment: metadata: creationTimestamp: null spec: strategy: {} template: metadata: creationTimestamp: null spec: containers: - name: "" resources: {} status: {} deps: "" function: | def foo(event, context): return "hello world" function-content-type: text handler: helloget.foo horizontalPodAutoscaler: // ... 省略 HPA 指标 runtime: python2.7 service: ports: - name: http-function-port port: 8080 protocol: TCP targetPort: 8080 selector: created-by: kubeless function: get-python type: ClusterIP timeout: "180"通过CRD实现了抽象的触发函数的不同事件源类型.
// Http Trigger apiVersion: kubeless.io/v1beta1 kind: HTTPTrigger metadata: labels: created-by: kubeless name: get-python namespace: default spec: function-name: get-python host-name: get-python.192.168.99.100.nip.io ingress-enabled: true path: func tls: false // Cronjob Trigger apiVersion: kubeless.io/v1beta1 kind: CronJobTrigger metadata: labels: created-by: kubeless function: scheduled-get-python name: scheduled-get-python namespace: default spec: function-name: scheduled-get-python schedule: '* * * * *' // Kafka Trigger apiVersion: kubeless.io/v1beta1 kind: KafkaTrigger metadata: labels: created-by: kubeless name: s3-python-kafka-trigger namespace: default spec: functionSelector: matchLabels: created-by: kubeless topic: s3-python topic: s3-python通过不同的CRD Controller完成对应资源对象的CRUD.
通过Deployment/Pod完成特定运行时的执行.
通过ConfigMap向运行时注入用户代码.
通过Init容器加载用户代码所需的依赖.
通过Service对内暴露函数.
通过Ingress对外暴露函数.
正如前文展示, Kubeless提供多种Trigger触发函数的执行:
- Http Trigger: 通过Http请求触发函数执行, 并以Http响应获取结果.
- CronJob Trigger: 通过Cron表达式触发函数执行.
- PubSub Trigger: 通过事件发布订阅的方式触发函数执行, 目前提供Kafka和Nats作为底层实现.
代码执行
如前文所述, Kubeless实际上提供多种语言的通用执行环境, 而实际代码则通过ConfigMap资源进行注入. 在项目kubeless/runtimes中, Kubeless提供了多种语言的包装运行时, 我摘取了Node.js版本的核心逻辑作为样例分析:
const vm = require('vm');
const path = require('path');
const Module = require('module');
const client = require('prom-client');
const express = require('express');
const morgan = require('morgan');
// ... 省略引用其他第三方库
const app = express();
// ... 省略应用 Express 中间件
// ... 生路参数读入和处理
// ... 省略 Probe/Metrics 路由注册
// ... 省略和执行上下文初始化
const script = new vm.Script('\nrequire(\'kubeless\')(require(\''+ modPath +'\'));\n', {
filename: modPath,
displayErrors: true,
});
function modRequire(p, req, res, end) {
// ... 省略对 require 的定制
}
// ... 省略参数处理, 错误处理函数封装
app.all('*', (req, res) => {
// ...省略外层 Cors 处理
const label = funcLabel(req);
const end = timeHistogram.labels(label).startTimer();
callsCounter.labels(label).inc();
// 创建沙箱上下文对象
const sandbox = Object.assign({}, global, {
__filename: modPath,
__dirname: modRootPath,
module: new Module(modPath, null),
require: (p) => modRequire(p, req, res, end),
});
try {
// 通过 Vm 模块运行用户代码
script.runInNewContext(sandbox, { timeout : timeout * 1000 });
} catch (err) {
if (err.toString().match('Error: Script execution timed out')) {
res.status(408).send(err);
// We cannot stop the spawned process (https://github.com/nodejs/node/issues/3020)
// we need to abruptly stop this process
console.error('CRITICAL: Unable to stop spawned process. Exiting');
process.exit(1);
} else {
handleError(err, res, funcLabel, end);
}
}
});
const server = app.listen(funcPort);
// ... 省略 Graceful Shutdown通过代码可以看出, Kubeless运行时实际上是一个Express App, 并且实现了简单的沙箱, 并通过Modules定制了沙箱内代码的require行为, 以实现模块注入和拦截. 当接收请求时, 将通过Node.js VM模块以新的V8上下文运行外部代码. 由于Node.js VM模块实现的缺陷(异步逻辑超时逃逸问题), 在某些情况下将不得不退出整个进程. 同时, 资源限制依赖外部Kubernetes的配额实现.
弹性伸缩
Kubeless的弹性伸缩依赖于Kubernetes提供的HPA实现.
Knative
Knative秉持了Google开源项目一贯的积木特色 - 优秀的工业设计, 自由的配置方式, 成堆的新概念和就是不给你开箱即用的设计思路(🤣).
Knative声明了很多Kubernetes CRD来定义函数的行为, 生命周期, 路由策略和事件的产生, 过滤, 分发和串并联规则. 用户可以通过如Kanico的项目完成从代码到镜像的过程, 基于Knative提供的资源定制复杂的消息触发规则, 并有Knative负责事件的分发和持久化, 函数的暴露和弹性伸缩. 由于Knative支持以GitHub/GitLab/BitBucket等代码托管平台作为事件源, 用户甚至可以基于Knative完成CI流程.
作为Google自家的产品, Knative未来在开源Serverless领域必然有不俗的竞争潜力, 但由于其发布时间较晚, 所以目前仍处于活跃开发状态, 官方文档与很多现有中文资料(翻译自早期版本)存在不少出入, 未来也仍有可能还有较大调整. 通过浏览Knative的文档, 容易发现本次调研的关注点, 即从代码到容器的过程和函数最终运行的方式, 均由Knative交由用户负责, 所以参考意义有限(主要是文档组织的很一般, 绕来绕去的, 颇有当年Kubernetes早期文档的风采, 懒得看)我没有继续深入了解. 这里放一张由OpenFaaS主要贡献者提供的OpenFaaS, Kubeless和Knative在2019年时的对比情况:
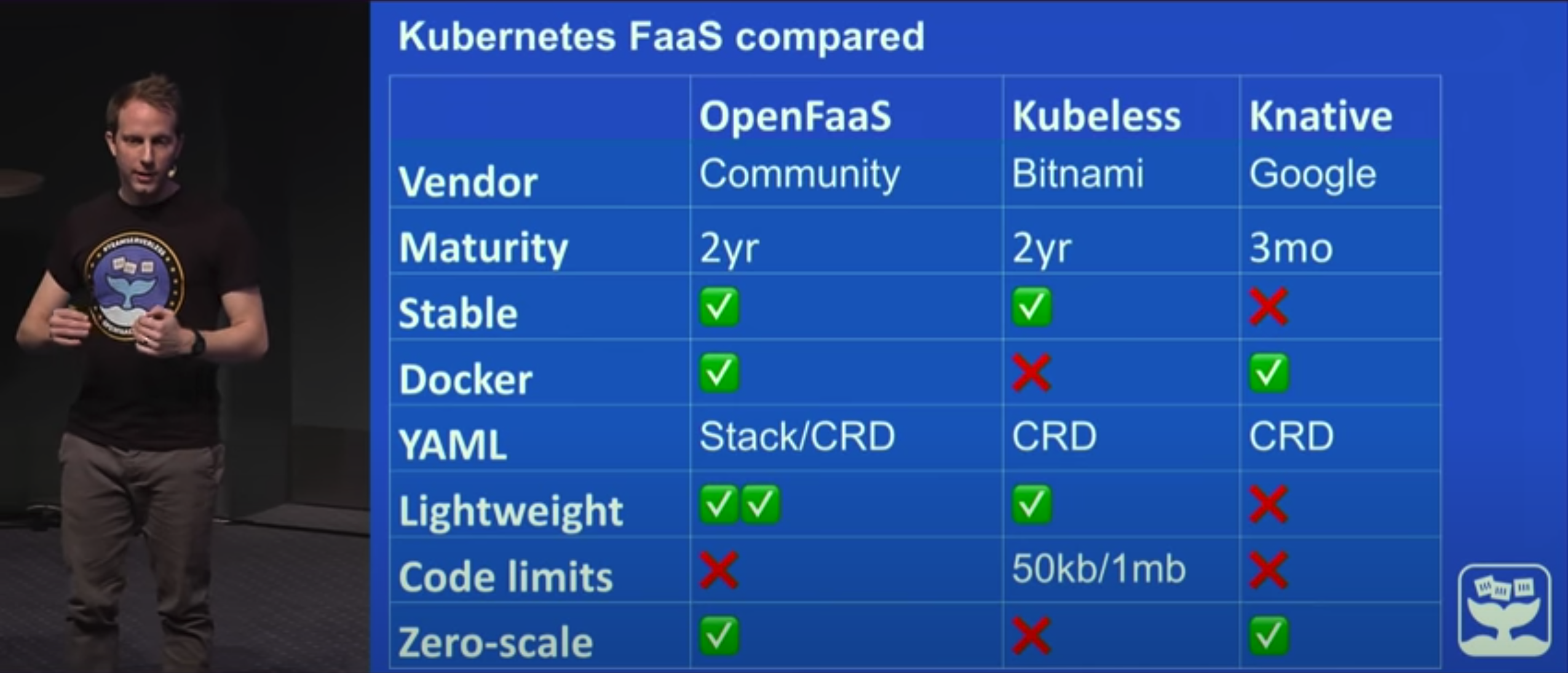
注: 上图中标注Kubeless限制代码容量为1.5Mb, 这是由于其代码体由ConfigMap向容器注入, 而ConfigMap作为持久化在Etcd中的实体受到其单条记录容量大小限制, 但Kubeless可以通过Url定义函数体位置绕过此限制.
Nuclio
Nuclio是我在调研上面三个项目时在社区发现的一个新兴的Serverless开源项目, 其主要特征是高性能和面向科学计算.
基本实现
Nuclio中, 由名为Processor的实现提供函数执行环境, 将事件(Event), 依赖数据(Data)和上下文(Context)传递至函数(Function), 并提供指标采集并管理函数生命周期. Processor可以以多种形式存在, 如与函数共同编译为二进制文件, 或与函数共同打包进镜像或作为独立容器运行于容器服务如Docker或编排工具平台如Kubernetes之上. 每一个函数都有对应的Processor, Processor为函数提供了跨平台的特性, 并且自身也会随流量变化参与弹性伸缩过程. Processor的架构如下:
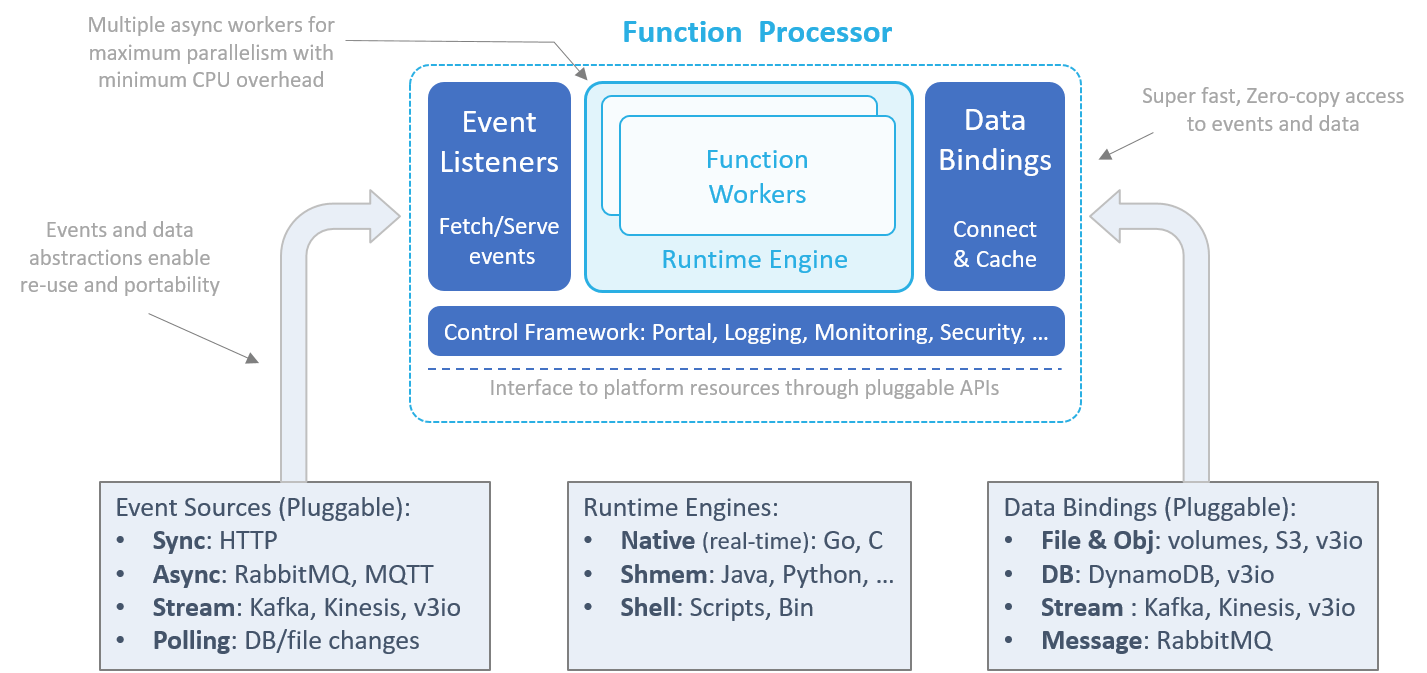
Event Listeners监听来自各类Trigger的事件, 或定期从外部获取事件, 系统中的事件遵循通用的Schema, 从而让事件与事件源与流转路径解耦. 同时Event Listeners还通过检查点, 本地/队列重试机制来保证函数执行的Exactly One/At Least One语义.
Runtime Engine初始化函数环境, 包括变量, 上下文, 日志环境和数据绑定等, 执行特定编程语言函数, 等待和获取结并返回至事件源. Runtime Engine下可能有多个并行的Worker(如Go routines, Python asyncio, Java Akka/Threads等)以提升CPU利用率. Runtime Engine目前主要有以下实现:
- Native: 针对C/C++/Go等编译至Native的语言.
- SHMEM: 针对Python/Java/Node.js等Processor能够基于内存管道实现Zero-Copy通信的编程语言.
- Shell: 针对通用可执行二进制文件或脚本, Processor通过标准输入输出流与Worker通信.
Data Bindings保持与外部文件, 对象, 数据库或消息系统的连接, 从而使Runtime Engine能够通过上下文将这些可复用的对象传递至Worker, 避免Worker反复连接, 鉴权和对相关资源的初始化带来的性能损耗. 此外, Data Bindings还能将函数依赖的外部数据进行统一的预处理或在外部维持缓存. Data Bindings和Runtime Engine机制是使Nuclio在性能方面显著优于其他开源Serverless实现的重要因素, Runtime Engine与OpenFaaS的Of-Watchdog Keep Warm思路类似但实现更加精细, 而Data Bindings这种资源复用的设计使Nuclio在科学计算领域的性能优势更加明显. 此外, Nuclio还支持函数代码对GPU的调用.
Control Framework提供日志, 监控指标等功能, 同时对底层平台进行抽象, 使最终组成的Processor拥有在多个平台上部署的能力.
在Nuclio中, 函数是事件驱动的, 事件由多种来源产生, 来源可以按行为分为以下类型:
- 同步Request/Response: 客户端发起请求, 服务端执行函数后立即响应结果, 如Http或其他RPC调用.
- 异步消息队列: 消息发布至Exchange, 继而分发至订阅者, 如调度事件, RabbitMQ等.
- 消息流(Message Streams): 有序消息集, 来自AWS Kinesis, Iguazio V3IO或Kafka等.
- 数据轮训或ETL: 对外部数据的检索和过滤结果集, 可以定期获取或由数据变更触发.

得益于前文提及的事件与事件源解耦的设计, 多个事件源可以与同一函数关联, 同一事件也可以触发多个函数.
代码执行
用户可以通过任意一种受支持的编程语言完成函数逻辑, 并提供一份配置文件, 其中描述函数所需的数据绑定, 环境资源, 鉴权信息和事件源. 最终, 用户的代码和配置将被打包为一个Artifact(二进制文件, Package或镜像, 取决于底层平台), 大致如下图:
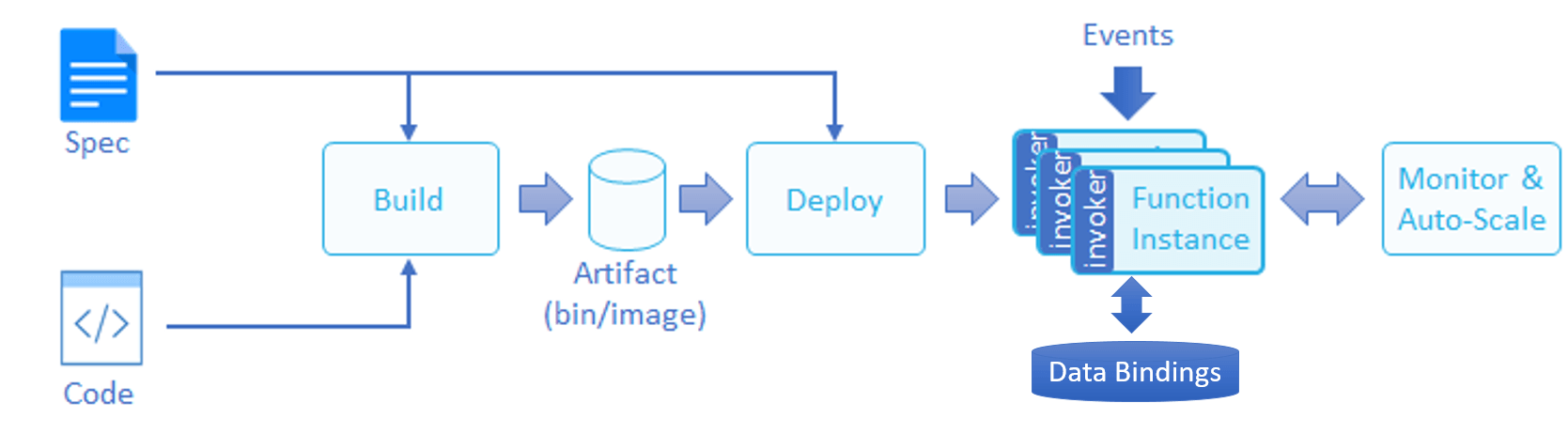
我们关注的主要是函数在运行后如何响应外部请求和执行代码逻辑获取运行结果, 所以可以直接查看Nuclio Worker相关代码(其实应该从Processor层开始看起, 但那样需要列出的代码量就比较多, Worker外层存在动态分配Workder的Allocator代码, 逻辑类似进程池实现, Runtime类型来自Configuration, 并于初始化Worker时通过构造参数传递, 代码如下:
// Worker 结构
type Worker struct {
logger logger.Logger
index int
runtime runtime.Runtime
statistics Statistics
structuredCloudEvent cloudevent.Structured
binaryCloudEvent cloudevent.Binary
eventTime *time.Time
}
// 创建新 Worker
func NewWorker(parentLogger logger.Logger,
index int,
runtime runtime.Runtime) (*Worker, error) {
newWorker := Worker{
logger: parentLogger,
index: index,
runtime: runtime,
}
// return an instance of the default worker
return &newWorker, nil
}
// 处理事件
func (w *Worker) ProcessEvent(event nuclio.Event, functionLogger logger.Logger) (interface{}, error) {
w.eventTime = clock.Now()
// 通过 Runtime 处理事件
response, err := w.runtime.ProcessEvent(event, functionLogger)
w.eventTime = nil
// ... 省略错误处理逻辑
}Worker在接收事件后直接转由Runtime实际执行, 而Runtime由外部工厂方法提供, 不同编程语言提供不同封装, 此处以Node.js为例, 其Runtime启动代码如下:
// 运行包装代码
func (n *nodejs) RunWrapper(socketPath string) (*os.Process, error) {
// 定位包装袋吗
wrapperScriptPath := n.getWrapperScriptPath()
// ... 省略错误处理
// 定位 Node.js 解释器位置
nodeExePath, err := n.getNodeExePath()
// ... 省略错误处理
// 注入环境变量
env := os.Environ()
env = append(env, n.getEnvFromConfiguration()...)
// 获取实际执行函数名称
handlerFilePath, handlerName, err := n.getHandler()
// ... 省略错误处理
args := []string{nodeExePath, wrapperScriptPath, socketPath, handlerFilePath, handlerName}
// ... 省略日志逻辑
// 启动 Node.js 解释器
cmd := exec.Command(args[0], args[1:]...)
cmd.Env = env
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stdout
return cmd.Process, cmd.Start()
}实际通过Node.js解释器运行了包装层代码, 并通过参数传递了实际代码文件的位置和需要执行函数的名称, 包装层代码如下:
let context = {
userData: {},
callback: async (handlerResponse) => {
context._eventEmitter.emit('callback', handlerResponse)
},
Response: Response,
logger: {
// ... 省略 Logger 相关参数
},
_socket: undefined,
_eventEmitter: new events.EventEmitter(),
}
function Response(body = null,
headers = null,
contentType = 'text/plain',
statusCode = 200,
bodyEncoding = 'text') {
this.body = body
this.headers = headers
this.content_type = contentType
this.status_code = statusCode
this.body_encoding = bodyEncoding
if (!isString(this.body)) {
this.body = JSON.stringify(this.body)
this.content_type = jsonCtype
}
}
// ... 省略工具函数
// 主函数
if (require.main === module) {
// ... 省略参数初始化
run(socketPath, handlerPath, handlerName)
.catch((err) => {
// ... 省略错误处理
})
}
// 实际运行逻辑
function run(socketPath, handlerPath, handlerName) {
// 加载实际函数代码文件
const functionModule = require(handlerPath)
// 从代码中加载执行函数
return findFunction(functionModule, handlerName)
.then(async handlerFunction => {
try {
// 允许用户初始化执行上下文
executeInitContext(functionModule)
} catch (err) {
// ... 省略错误处理
}
// 执行函数逻辑并通过 Socket 通信将结果回传
return connectSocket(socketPath, handlerFunction)
})
}
// 从模块中查找函数
async function findFunction(functionModule, name) {
// ... 省略具体逻辑
// Nuclio 在此处实现了带有时间限制的重试逻辑, 原因不明.
}
// 通过上下文执行函数
function executeInitContext(functionModule) {
const initContextFunction = functionModule[initContextFunctionName]
// 允许用户初始化执行上下文
if (typeof initContextFunction === 'function') {
return initContextFunction(context)
}
}
// 执行函数逻辑并通过 Socket 通信将结果回传
function connectSocket(socketPath, handlerFunction) {
const socket = new net.Socket()
console.log(`socketPath = ${socketPath}`)
if (socketPath.includes(':')) {
// ... 省略 TCP Socket 连接逻辑
} else {
// ... 省略 UNIX Socket 连接逻辑
}
// 将 Socket 注入执行上下文中
context._socket = socket
socket.on('ready', () => {
// 通过 Socket 与 Processor 通信, 告知 Processor 包装层启动完成
writeMessageToProcessor(messageTypes.START, '')
})
socket.on('data', async data => {
// 当 Processor 通过 Socket 将事件传递到包装层时调用用户函数逻辑计算结果
let incomingEvent = JSON.parse(data)
await handleEvent(handlerFunction, incomingEvent)
})
}
// 调用用户函数逻辑计算结果
async function handleEvent(handlerFunction, incomingEvent) {
let response = {}
try {
// 参数准备
incomingEvent.body = new Buffer.from(incomingEvent['body'], 'base64')
incomingEvent.timestamp = new Date(incomingEvent['timestamp'] * 1000)
// ... 省略执行时间统计
// 回调逻辑封装
const responseWaiter = new Promise(resolve => context
._eventEmitter
.on('callback', resolve))
// 执行用户函数
handlerFunction(context, incomingEvent)
// 等待用户代码执行
const handlerResponse = await responseWaiter
// ... 省略执行时间统计
// 格式化执行结果
response = responseFromOutput(handlerResponse)
} catch (err) {
// ... 省略错误处理
response = {
body: `Error in handler: ${errorMessage}`,
content_type: 'text/plain',
headers: {},
status_code: 500,
body_encoding: 'text'
}
} finally {
// 通过 Socket 向 Processor 传递结果
writeMessageToProcessor(messageTypes.RESPONSE, JSON.stringify(response))
}
}
// 格式化执行结果
function responseFromOutput(handlerOutput) {
let response = {
body: '',
content_type: 'text/plain',
headers: {},
status_code: 200,
body_encoding: 'text',
}
// ... 省略结果解析和拼装
return response
}
// 通过 Socket 向 Processor 传递结果
function writeMessageToProcessor(messageType, messageContents) {
context._socket.write(`${messageType}${messageContents}\n`)
}通过代码可以看出, 包装层对上下文环境进行初始化, 与Processor建立了Socket通信, 并在接收到事件时调用用户代码并将结果回传至Processor.
弹性伸缩
与其他开源项目提供的基于性能指标进行弹性伸缩的机制不同, 由于Nuclio还关注函数对大规模数据处理的能力, 因此对于如Kafka这种可分区的消息流, Nuclio允许按分区创建Processor实例进行处理, 或将N个资源(Shard/Partition/Task等)动态分配个M个Processor处理计算中的错误.
总结
得益于Kubernetes即其他云原生项目的成熟, 目前开源的FaaS本身的实现都不算特别复杂. 即使是商业的Serverless方案, 如阿里云, 其核心概念, 实现甚至配置也与前文这些开源项目类似.
通过这些开源项目, 不难看出, 当前阶段的Serverless主要关注点在于抽象执行环境, 自动化的代码构建和弹性伸缩. 可以说, 代码托管平台+CI+Kubernetes+HPA即组成了最简单的Serverless平台.
此外, “Serverless”, “FaaS”与通用的安全沙箱并不等价, 如前文所示, 只有Kubeless的Node.js运行时实现了非常简单的沙箱, 而大部分Serverless出于性能考虑都有不同形式的Keep Warm机制来避免反复冷启动, 这一点我在使用阿里云的Serverless服务时也发现类似的情况. 这种短期有状态的机制使我们不能将直接将该服务作为通用的安全沙箱, 用户的恶意代码有可能影响后续其他请求的结果, 但也是此特性能够让我们实现热脚本的短期缓存.
许可协议: CC BY-NC-SA 4.0
本文链接:https://blog.angelmsger.com/开源Serverless项目概览/