探索Node.js原理
最近因为工作的原因学习了Node.js, 我之前接触JavaScript相对比较少, 所以这段时间恶补了不少东西, 最近读到了JSBlog中关于Event Loop机制和Node.js原理的系列文章, 实在是很不错. 我把它翻译并整理了一下以便分享给更多人.
Node.js
Node.js与其他服务端开发平台最大的不同在于其处理I/O的方式. 很多文章将Node.js定义为一个非阻塞的, 事件驱动的, 基于Google开发的V8引擎的平台, 要理解这些标签的含义, 核心就在于本文的主题, Event Loop.
简化的EventLoop
Node.js工作在事件驱动模型之上, 这个模型包含一个事件分发器和一个事件队列, 这种模型也被称为反应器模式(Reactor Pattern). 通俗的说, 当I/O请求到来时, 事件分发器(Event Demultiplexer)将其分发至指定设备去执行, 此时调用者并非阻塞等待操作结果, 而是继续执行队列中的其他任务. 当I/O操作执行完毕后, 事件分发器将此次I/O操作的结果及对应的回调函数加入事件队列, 直至调用者处理至此事件并执行回调函数. 这是一个半无限循环, Node.js的执行器会轮询事件队列, 直至队列中没有等待执行的回调并且没有其他未完成的I/O操作. 此过程的简图可以表示为:
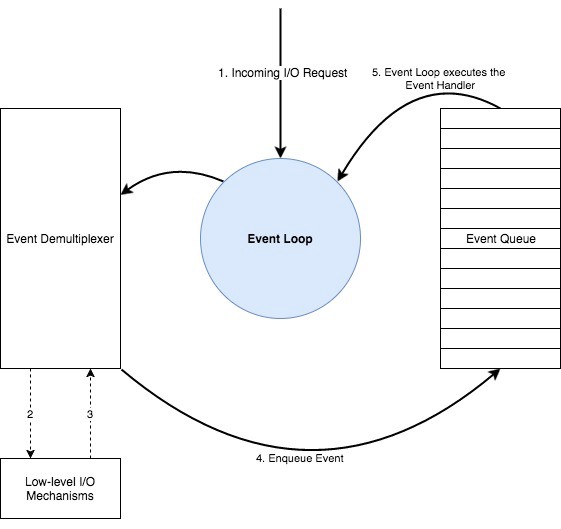
网上很多文章对Node.js的执行模型探索到此为止, 但实际上这只是一个非常简化的模型, 很多时候甚至无法帮助我们理解一段程序, 比如:
setTimeout(() => console.log('set timeout1'), 0);
Promise.resolve().then(() => console.log('promise1 resolved'));
Promise.resolve().then(() => {
console.log('promise2 resolved');
process.nextTick(() => console.log('next tick inside promise resolve handler'));
});
Promise.resolve().then(() => console.log('promise3 resolved'));
setImmediate(() => console.log('set immediate1'));
process.nextTick(() => console.log('next tick1'));
setImmediate(() => console.log('set immediate2'));
process.nextTick(() => console.log('next tick2'));
Promise.resolve().then(() => console.log('promise4 resolved'));
setTimeout(() => {
console.log('set timeout2');
process.nextTick(() => console.log('next tick inside timmer handler'));
}, 0);如果你能够回答上述代码的执行结果, 说明你对EventLoop是略有理解的, 它的结果应当是:
next tick1
next tick2
promise1 resolved
promise2 resolved
promise3 resolved
promise4 resolved
next tick inside promise resolve handler
set timeout1
set timeout2
next tick inside timmer handler
set immediate1
set immediate2如果你没能完全答对的话, 本系列文章应该能为你补齐一些关于Node.js原理方面的知识.
真实的EventLoop
LibUV
实际上Node.js中的时间队列并非只有一个简单的队列, I/O事件也并非全部的事件类型.

事件分发器在不同操作系统下有不同的底层实现方案, 如Linux下的epoll, BSD下的kqueue, Windows下的IOCP和Solaris下的event ports等. 网络I/O的非阻塞实现可由这些底层接口提供, 而Node.js需要做的则是封装不同平台的实现, 从而实现上文中的EventLoop机制, 进而最终的程序员能够以异步的方式进行网络编程.
令Web程序阻塞操作通常并非只有网络I/O, 还有文件I/O以及基于文件I/O的其他服务如DNS等. 很多操作系统并不提供针对每一类操作都提供异步接口. Node.js为了实现前文提及的完全反应器模式, 在尽可能利用底层异步非阻塞特性的同时, 也不得不维护线程池来解决这些问题. 由此也可以指出, 一些开发者简单的认为Node.js只有一个线程, 异步操作完全依赖操作系统接口, 或反之完全依赖线程池执行所有的异步操作都是不对的.
Node.js也会将一些CPU密集型任务接口的异步版本交由后台执行, 如crypto和zlib下的一些方法.
为了最终向编程人员创造一个非阻塞的开发平台, 首先需要为前文提及的各类事件封装一个跨平台的异步操作层, 在Node.js中, 这就是LibUV. 下面这幅图摘自官方文档, 其表述的也是上文所提的内容.
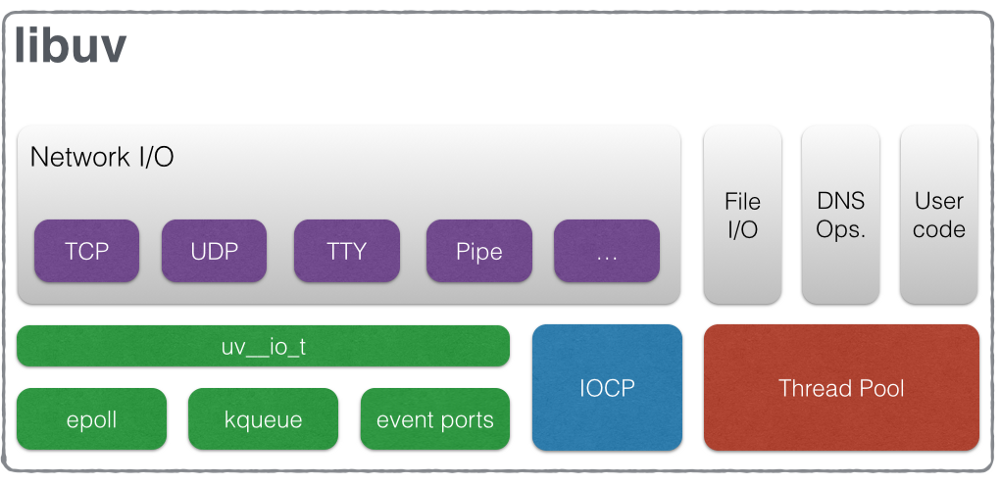
事件队列
LibUV向Node.js提供了为实现EventLoop所需的基础功能, 包括事件队列机制. 在反应器模式中, 事件队列是一个不断有事件出入队, 并被执行器不断轮训的数据结构. 相较于反应器模式中的简化模型, Node.js的实际实现更加复杂. 在Node.js中并非只有一个队列, 而是针对不同的事件类型存在多个队列.
LibUV为实现EventLoop建立了4个队列, 分别是:
- Timeout & Interval: 到期的计时器的回调, 如
setTimeout或setInterval设定的时间条件满足时的回调 - I/O Events: 完成的I/O操作时的回调,如
fs.readFile指定的文件被读取完毕 - Immediates: 通过
setImmediate增加的回调 - Close Handlers: 所有
close事件的回调
尽管此处都称为队列, 但实际上他们的实现方式从数据结构的角度来说并非全是队列, 比如Timer & Interval就是由一个小顶堆实现的.
除了这4个由LibUV实现的队列外, Node.js本身还实现了两个”中间”队列, 分别是:
- Next Tick: 通过
process.nextTick添加的回调 - Promise Microtasks: 由
Native Promise(而不是q或BlueBird这类第三方库)产生的回调
那么这些队列如何协同工作实现最终的EventLoop呢? 先看一幅图:
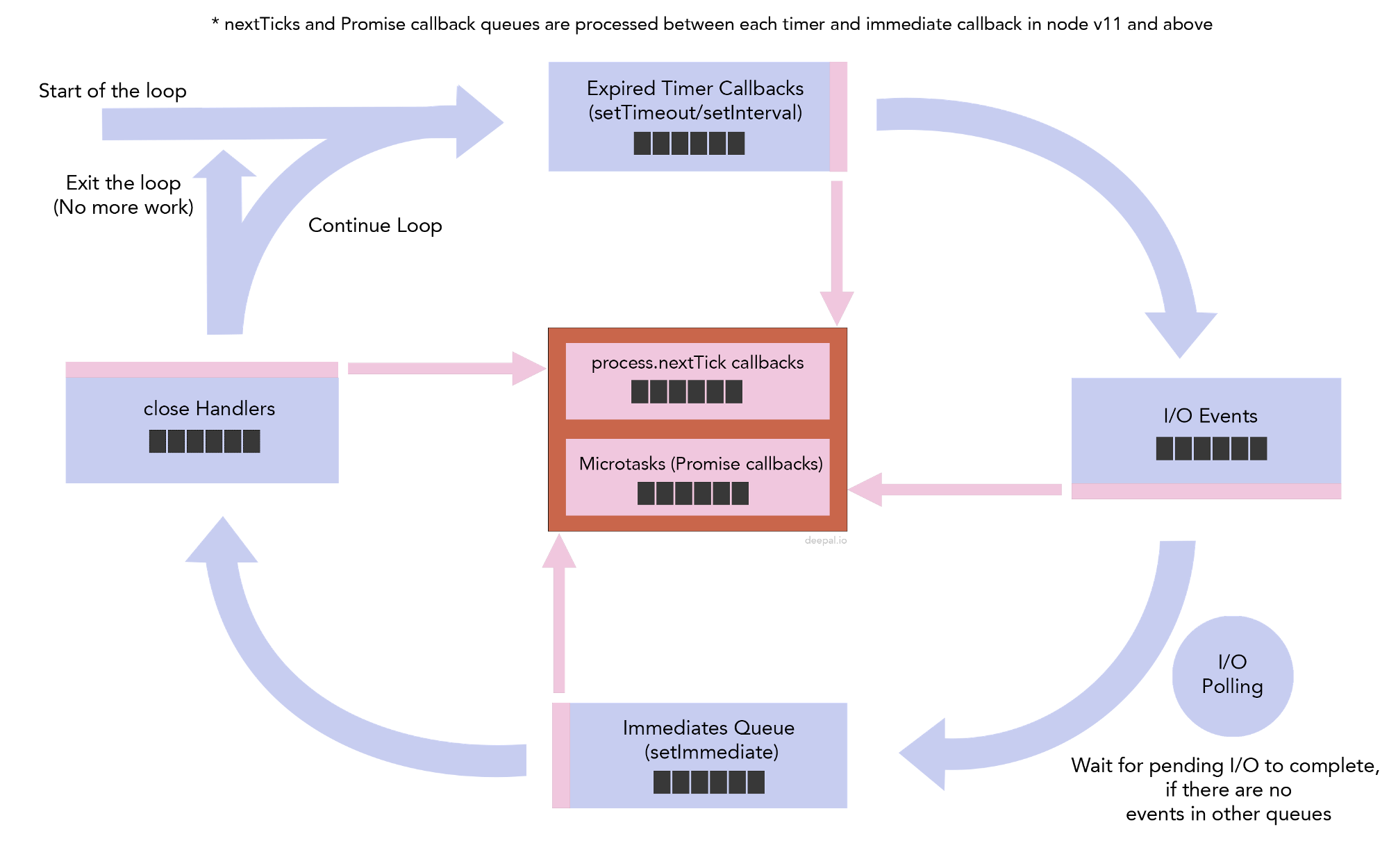
如图所示,EventLoop从Timer & Interval队列开始, 顺序并循环遍历每个队列. 执行器轮询一个队列的过程被称作一个阶段(Phase). 当所有队列皆为空, 且没有其他未完成的后台任务时, 程序结束. 此外, 在任意两个阶段中间, Node.js还会执行自身实现的两个”中间”队列中的全部回调, 即Node.js保证在执行LibUV的当前阶段后, 下一阶段前, 自身队列被清空.
在这两个”中间”队列中, Next Tick队列拥有更高的优先级. Promise Microtasks队列中的回调任务来自Node.js Native Promise, 不包含第三方Promise实现如q或BlueBird, 这两个库是在ES6提供标准的Promise实现之前的替代品, 两者实现方式也不相同, 默认情况下, q基于Next Tick队列而BlueBird基于Immediate队列.
前文提到Promise Microtasks队列中的回调任务来自Node.js Native Promise, 不包含第三方Promise实现如q或BlueBird, 这些库是在ES6提供标准的Promise实现之前的替代品, 他们在内部有着不同的实现, 默认情况下, q基于Next Tick队列而BlueBird基于Immediate队列.
这就带来两个问题, 一是定时器可能不会准时执行, 因为执行器必须先完成前面队列的任务, 才会循环至Timer & Interval队列. Node.js只会保证当执行器循环至此队列时那些到期甚至过期的定时器回调一定会被执行. 二是如果我们不断通过process.nextTick向Next Tick队列添加待执行的回调函数, 那么理论上后续的如I/O队列会陷入饥饿, 永远不会执行, 此处以实验验证:
function addNextTick() {
process.nextTick(addNextTick);
}
process.nextTick(addNextTick);
setTimeout(() => console.log('never access here.'), 0);执行后程序没有任何输出, 与此前设想一致, 因此在实际开发中应当避免这种情况. 在Node.js的早期版本中曾有对Next Tick队列深度的限制, 但后续版本中因为其他原因而移除了该限制.
在Node.js 11之后, 上述逻辑产生了变化, 我们将在后文中对该更新进行说明.
问题回顾
现在, 我们可以开始回顾文章开始时的那段代码了:
setTimeout(() => console.log('set timeout1'), 0);
Promise.resolve().then(() => console.log('promise1 resolved'));
Promise.resolve().then(() => {
console.log('promise2 resolved');
process.nextTick(() => console.log('next tick inside promise resolve handler'));
});
Promise.resolve().then(() => console.log('promise3 resolved'));
setImmediate(() => console.log('set immediate1'));
process.nextTick(() => console.log('next tick1'));
setImmediate(() => console.log('set immediate2'));
process.nextTick(() => console.log('next tick2'));
Promise.resolve().then(() => console.log('promise4 resolved'));
setTimeout(() => {
console.log('set timeout2');
process.nextTick(() => console.log('next tick inside timmer handler'));
}, 0);结合前文的EventLoop图示, 该段代码运行后:
- 通过
nextTick添加的回调将被首先执行. - 由
Promise添加的回调其次. - 由于在阶段变更前, Node.js会保证Next Tick队列和Promise Microtasks队列清空, 而我们在Promise回调函数中向Next Tick队列重新添加了回调, 因此Node.js在转换至下一阶段前需要执行该回调.
- 执行器进入Timer & Interval队列阶段, 由于代码中添加了0毫秒过期的定时器函数, 因此他们将被执行.
- 在执行器将Timer & Interval队列中的回调执行完毕后, 进入I/O队列前, 会再次检查Next Tick队列和Promise Microtasks队列, 因此在定时器函数中添加至Next Tick队列中的回调将被执行.
- 执行器进入I/O队列, 由于该队列为空, 因此将检查Next Tick队列和Promise Microtasks队列以准备进入下一阶段, 由于这两个队列也为空, 因此直接进入Immediate队列阶段.
- 执行器执行Immediate队列中的回调.
在文章起始处, 我们给出了这段代码的实际执行结果, 大家可以与上述逻辑对比验证.
更进一步
下图是Node.js的架构:
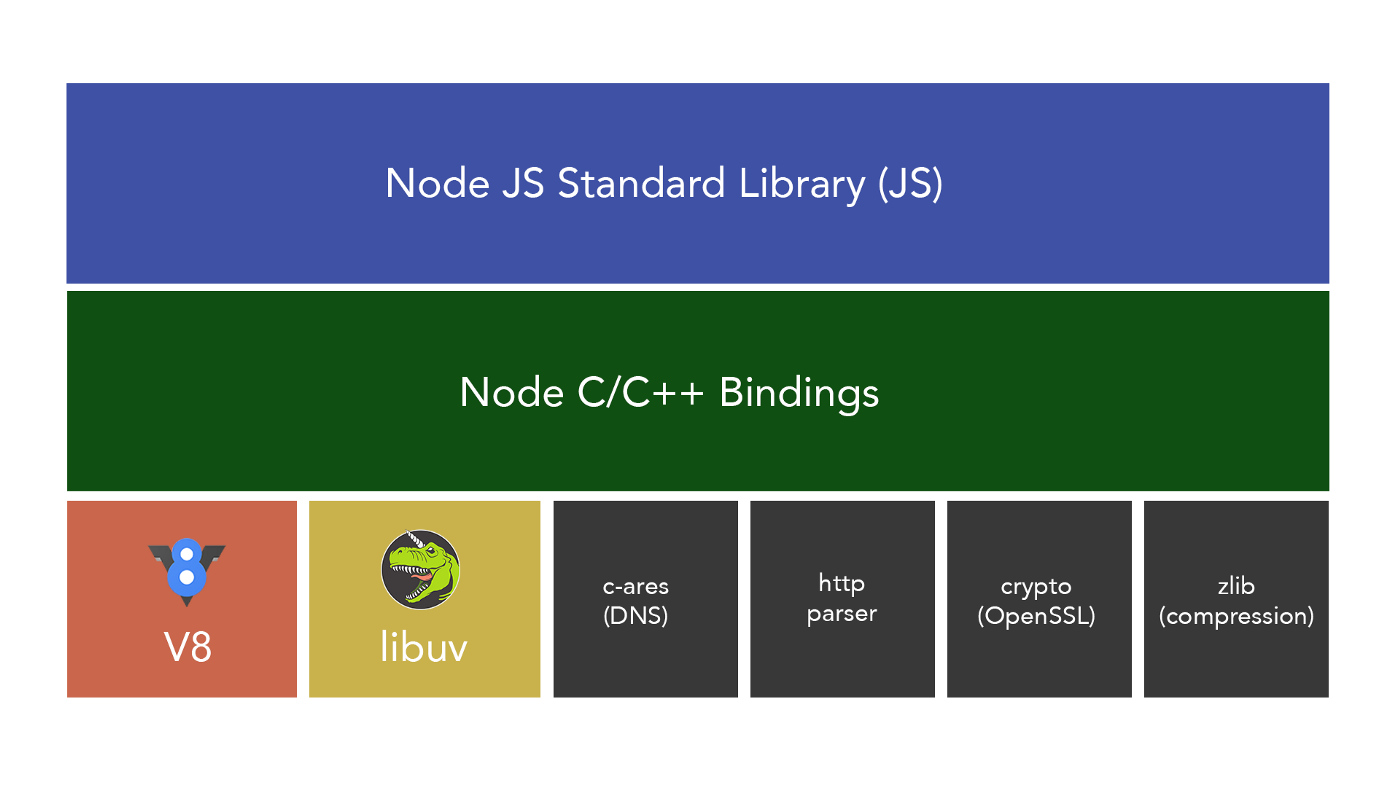
可以看到, LibUV处于较Node.js更低层, 而我们前文讨论的EventLoop, 是从Node.js的视角看的, 如果我们继续下探至LibUV, 会发现情况其实更加复杂, 如图所示:
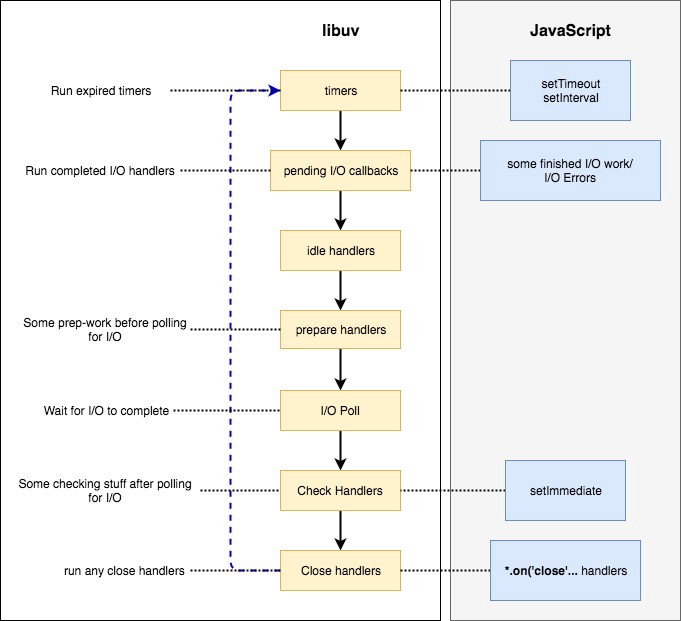
右侧是前文描述的4个阶段, 而左侧是在LibUV中实际对应的7个阶段.
- Timers: 通过
setTimeout和setInterval添加的回调. - Pending I/O Callbacks: I/O完成或出错后的回调.
- Idle Handlers: 一些LibUV内部行为.
- Prepare Handlers: I/O行为准备.
- I/O Poll: 可选的阻塞并等待I/O完成行为.
- Check Handlers: I/O行为后的检查回调, 通常对应于代码中通过
setImmediate添加的回调 - Close Handlers:
'close'事件回调
LibUV关于EventLoop的核心实现位于core.c源文件中的uv_run函数, 这段代码与前文的图示和描述相对应:
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
// EventLoop 是否仍然有效, 判定条件:
// 1. 仍有活动回调
// 2. 仍有 pending 中的异步操作
// 3. 仍有'close'回调
// 三个条件为或关系
r = uv__loop_alive(loop);
if (!r)
// 更新定时器时间
uv__update_time(loop);
// 在退出位无效时循环
while (r != 0 && loop->stop_flag == 0) {
// 更新定时器时间
uv__update_time(loop);
// 运行 Timer & Interval 队列中的回调
uv__run_timers(loop);
// 运行 I/O 队列中的回调, 队列若为空返回 0, 否则返回 1
ran_pending = uv__run_pending(loop);
// LibUV 内部操作
uv__run_idle(loop);
// 准备 I/O
uv__run_prepare(loop);
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
// timeout 获取逻辑, 判定条件:
// 1. 没有 stop_flag
// 2. active_handlers 和 active_reqs 均为空
// 3. idle_handlers 为空
// 4. pending_queue(I/O 事件回调队列)为空
// 5. closing_handlers 为空
// 满足以上全部条件时, 返回距离下一个到期定时器的时间, 否则返回 0
timeout = uv_backend_timeout(loop);
// 仅在 timeout 不为 0 时阻塞并等待 I/O
uv__io_poll(loop, timeout);
// 运行 Check 队列中的回调
uv__run_check(loop);
// 运行 Close Handlers 队列中的回调
uv__run_closing_handles(loop);
// 关于 EventLoop 的运行模式可以查看其文档, 此处略过说明
if (mode == UV_RUN_ONCE) {
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
if (loop->stop_flag != 0)
loop->stop_flag = 0;
return r;
}上述代码的逻辑相对还是比较清楚的. I/O Pull队列初见时容易引人生疑, “Node.js不是非阻塞的吗, 为什么会有等待I/O的阶段?”, 通过uv_backend_timeout的条件可以看到, Node.js几乎只会在”无事可做但又不能结束”的状态下才会进入有限时间的阻塞状态. 此外值得一提的是, Node.js的文件I/O是依赖后台线程阻塞执行的, 默认情况下, Node.js的线程池大小只有4, 结合前文提到, Node.js还会将一些CPU密集型的库函数的异步版本也交由后台线程执行, 这类操作的堆积也会成为Node.js的性能瓶颈之一.
Node.js 11
通过对前文的学习, 想必你已经能推算出下述代码的运行结果:
setTimeout(() => console.log('timeout1'));
setTimeout(() => {
console.log('timeout2');
Promise.resolve().then(() => console.log('promise resolve'));
});
setTimeout(() => console.log('timeout3'));在Node.js发布版本11之前, 一切确实如前文所述, 但在Node.js 11之后, 这一行为却改变了:
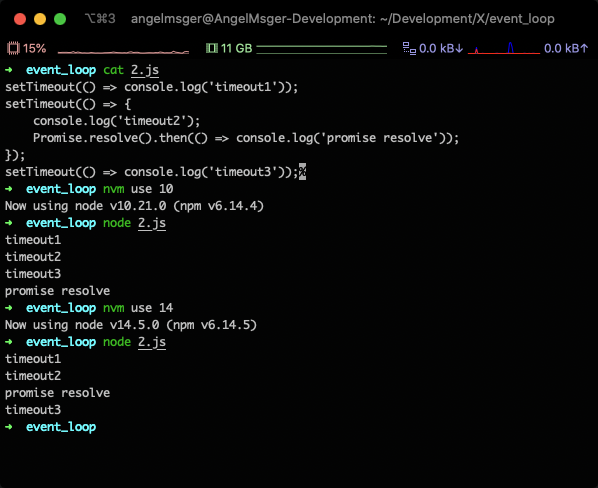
在Node.js 11之后, 每次执行setTimeout, setImmediate之后, 都会检查Next Tick和Promise Microtasks两个队列, 如果非空, 则优先执行其中的回调. 这种行为的改变是为了使Node.js的行为与浏览器的行为保持一致.
Node.js多线程
在Node.js诞生后的很长一段时间里, 他并没有官方的多线程支持, 这是因为Node.js是基于JavaScript的, 而JavaScript是单线程的. 此前, 如果我们一定要通过Node.js做一些CPU密集型任务, 通常会考虑通过child_process或cluster模块编写多进程代码. 但在v10.5.0版本中, Node.js引入了worker_threads模块以支持用户级多线程, 并在v12 LTS版本后标将其记为稳定模块.
worker_threads模块是一种解决方案而非语言特性, 换句话说, 他并非为JavaScript本身语言添加了并发特性, 每个Worker是独立的V8实例, 拥有自己的EventLoop, 只是相较子进程的方案而言. 这些Worker可以共享内存.
在我看来Node.js提供的这些用于并发编程的模块, 更多的是对自身功能的补足, 而非鼓励使用的特性, 在性能, 易用性等方面都没有明显的优势.
总结
本文对EventLoop的实现管中窥豹. EventLoop, 或者说LibUV, 是Node.js平台的核心, 也是Node.js区别于其他编程语言的魅力所在. 认识EventLoop, 能够帮助我们对代码的执行逻辑有清醒的认识, 也是定位相关问题的必要基础知识.
参考资料
许可协议: CC BY-NC-SA 4.0
本文链接:https://blog.angelmsger.com/探索Node-js原理/